Graphcore Researchが、革新的なコンピュータビジョンモデルEfficientNet-B4の学習をGraphcoreの最新のハイパースケールIPU-POD128およびIPU-POD256システム上で高速化し、2時間弱で収束させた方法をご紹介します。
EfficientNetとは?
EfficientNetファミリーのモデルは、比較的少ないパラメータとFLOPsで高いタスク性能を達成する、コンピュータビジョンの最先端を示すものです。しかし、レガシーなプロセッサアーキテクチャではEfficientNetの効率の良さを引き出せないため、実際に採用するには限界があります。
例えば、EfficientNetsのdepthwise畳み込みやグループ畳み込みはどちらも、通常の畳み込み演算と比較すると表現力が高く、計算効率が高い一方で、演算強度(データ移動に対する演算の割合)が低いという特徴があります。このタイプの演算は、メモリとプロセッサコア間のデータ転送量が多いため、GPUでは性能が低下します。それに比べてメモリセントリックアーキテクチャを採用するIPUでは、モデル全体とそのアクティベーションをチップ上に残すことができ、そのようなコストの高いデータの移動が軽減されます。
さらに、MIMD(複数命令、複数データ)パラダイムを採用するIPUでは、モデルや学習手順の多次元にわたるきめ細かな並列処理が可能です。これにより、小さな畳み込みを用い、ごく少数のデータサンプルを並列に処理しながら、高いスループットを実現できます。それに対し、SIMD(単一命令、複数データ)アーキテクチャを採用するGPUでは並列処理に限界があり、機械学習アルゴリズムの設計とハードウェア上で達成可能なスループットの間でトレードオフを強いられます。
このようなIPUハードウェアでの高速化により、さらに多くのイノベーターやAI専門家が実世界の大規模実装にEfficientNetモデルの高効率を活用できるようになります。
GitHubで公開されているGraphcoreのサンプルでは、EfficientNetファミリーのモデルなど、誰でもすぐにIPUで使える人気のモデルが幅広く提供されています。 今回のエクササイズでは、AI分野でEfficientNetの性能のベンチマーク評価によく利用されるEfficientNet-B4を検討します。
スループットの最適化
モデルの分散
複数のIPUにモデルを分散させる方法は、データ並列レプリケーションや
パイプラインモデル並列化など、数多く存在します。EfficientNet-B4のサイズとIPU-PODのスケールを考えると、データ並列とモデル並列を組み合わせることで最良の結果が得られます。またPoplarソフトウェアスタックを使うことで、フレームワークレベルで様々な分散設定を簡単に試すことができ、様々なタイプの並列処理を構成する最適な方法を短時間で探し出すことができます。
GitHubのサンプルにあるEfficientNet-B4のデフォルトの構成では、4つのIPUでモデルがパイプライン化されています。パイプラインのステージ数が増えると、パイプラインの充填と排出に多くの時間がかかり、IPU全体の利用率が低下します。また、IPU全体のワークロードのバランスについて、より慎重に対処しなければなりません。このような課題は、パイプラインのステージ数を2つに減らすことができれば解決されます。またこれにより、レプリカの数を2倍にすることもできます。
EfficientNet-B4を搭載するIPUの数を2つに抑えるために、当社は3つの手法を採用しています。
- 16ビット浮動小数点演算とマスターウェイトを使用する
- ローカルバッチのサイズを小さくする
- Graphcore Researchの『Making EfficientNet More Efficient(EfficientNetをより効率的にする)』という題のブログと論文で紹介されている、G16バージョンのEfficientNetを使用する
IPUは16ビットと32ビットの浮動小数点数表現をネイティブにサポートしているので、アプリケーションに存在する様々なテンソルの表現を柔軟に調整できます。FP32のマスターウェイトを保存しなければならない場合もありますが、その場合、学習中はモデルパラメータのコピーが完全な精度で保存されます。私たちはEfficientNetについて、FP16のマスターウェイトを使用し、ウェイトの更新に確率的丸め込みを採用しても性能を維持できることを発見しました。
アクティベーションの保存に必要なメモリはバッチサイズに比例して大きくなるため、学習に影響を与えずにアクティベーションのオーバーヘッドを削減する方法を検討することが重要です。アクティベーションの再計算は、バックワードパスで必要になった場合にアクティベーションを再計算するメソッドです。これにより、コンピュート機能とメモリのトレードオフがシンプルになります。このメソッドはPoplarで利用でき、パイプラインAPIを通じてフレームワークレベルで簡単にアクセスできます。EfficientNet-B4では、アクティベーションの再計算を利用して、ローカルバッチサイズを3に収めることができます。この構成では、ミニバッチを分散させるレプリカの数が2倍になるので、4ステージのパイプライン設定よりも多くのサンプルを並列処理できます。この作業には、バッチに依存しない正規化メソッドであるGroup Normを使用しています。このモデルにはバッチ間の依存性がないため、メモリに収められるローカルバッチサイズに制限がなく、単に勾配蓄積(Gradient Accumulation:GA)の数を増やすことで、思い通りのグローバルバッチサイズを達成できるうえ、モデルの学習ダイナミクスに影響を与えることなくメモリ内のアクティベーションを適合させることができます。
私たちは、畳み込みグループのサイズを1から16に増やす(その後、FLOPsとパラメータの増加を相殺するために拡張率を下げる)ことで、EfficientNetのMBConvブロックのメモリオーバーヘッドを削減しています。この点については、Graphcore Researchの『
Making EfficientNet More Efficient(EfficientNetをより効率的にする)』という論文で詳しく紹介されているほか、当社の
ブログでも要約されています。このタイプのモデルでは、メモリを節約できる点に加え、ImageNetの検証精度が向上するという利点もあります。
これら3つの手法により、オプティマイザの状態をストリーミングメモリにオフロードすることなく、わずか2つのIPUでモデルを適合させることができ、高いスループットで学習を行うことが可能になります。
データIO
IPU-PODのような強力なAIアクセラレータシステムで機械学習モデルを学習する場合、処理に必要となる十分なデータをホストからモデルに供給することが、共通のボトルネックになります。コマンドラインユーティリティのPopRunを使うと、複数のプログラムインスタンスに分散してアプリケーションが起動されるので、このボトルネックを軽減できます。各インスタンスのIOは、対応するホストサーバによって管理され、モデルにデータを供給する速度に制限されることなく、様々なIPU-PODシステムにモデルをスケールアップできます。
本来、ImageNetのデータセットはINT-8で表現されていますが、前処理の一環として、ホスト上でより高精度の浮動小数点データ型にキャストされるのが一般的です。IPU上にデータがある時点でこの変換を行うと、より低い精度で入力データをIPUにストリーミングできるので、通信オーバーヘッドの削減につながります。これにより、モデルにデータが供給される速度を高めて、スループットをさらに向上させることができます。
IPU内部とIPU間のデータ移動は、
バルク同期並列処理(BSP)実行スキームで行われます。BSPでは、タイル(IPUプロセッサコア)がローカルでの計算と、他のタイルとのデータ交換を交互に行い、その間に同期ステップが実行されます。
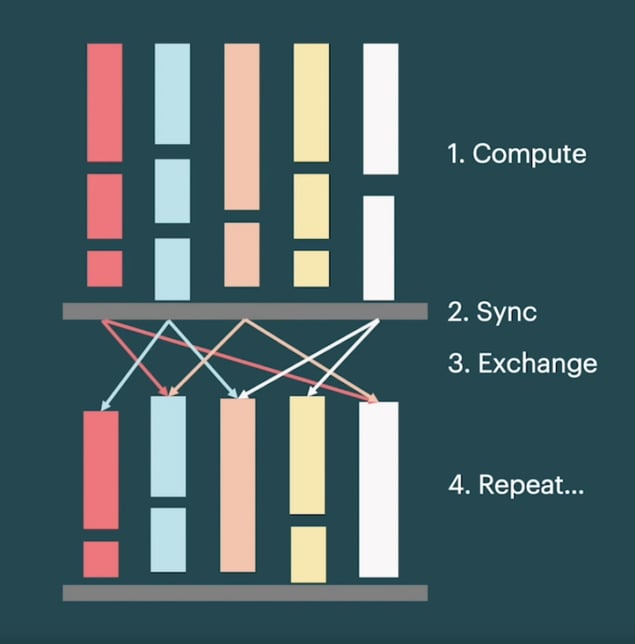
この実行スキームを使用するPoplarは、数十万タイルに及ぶ演算を効率的に並列化できます。IOが制限されるアプリケーションでは、すべてのタイルでナイーブなBSPパラダイムを使用すると性能が低下してしまいます。その点においてPoplarは、一部のタイルを同期させることなくデータのストリーミングに特化させ、残りの計算タイルはBSPパラダイムで実行することで、この問題に対処しています。IOをオーバーラップさせることでIOのボトルネックを軽減しつつ、高度にスケーラブルな実行スキームも可能にしているのです。私たちは、前述のメソッドと組み合わせて、IPUあたり1472タイルのうち32タイルをIOオーバーラップに割り当て、最大3つのデータバッチをプリフェッチすることで、すべてのシステムスケールで素晴らしいスループットを達成できることを明らかにしました。
バッチサイズのスケーリング
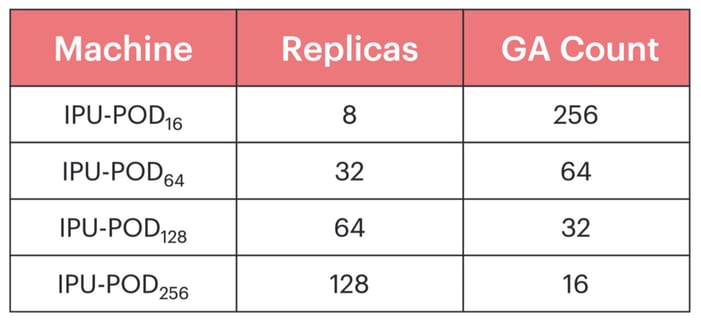
IPU-POD128やIPU-POD256のような大規模なシステムで学習するには、大きなグローバルバッチサイズを使用することが有効です。そのようにすることで、データサンプルの処理を多数のレプリカで並列化しながら、各レプリカに十分な作業量を確保して、効率を維持することができます。 さらに、レプリカ間で勾配を減らすコストをならすために、レプリカ間で通信して重みづけを更新する前に、複数の前進パスと後退パスで勾配を局所的に蓄積する、いわゆる勾配蓄積(GA)を行います。したがってグローバルバッチサイズは、ローカルバッチサイズ、レプリカ数、および勾配蓄積数の積になります。
ベースラインには、『Making EfficientNet More Efficient(EfficientNetをより効率的にする)』を参考に768のグローバルバッチサイズを使用しています。ローカルバッチサイズを3にした場合、IPU-POD256では1回の学習イテレーションで2つのローカルバッチしか得られません。これではパイプラインの設定を十分に活用できず、コストのかかる重みづけの更新を頻繁に行う必要があります。しかし、単純にグローバルバッチサイズを大きくすると、一般化の性能低下を招きます。この現象は、多くの機械学習アプリケーション、
特にコンピュータビジョンに共通するものです。したがって、すべてのIPU-PODシステムで高いスループットを維持できる大きさでありながら、優れた統計的有効性も同時に達成できる小さなグローバルバッチサイズを求めることになります。
私たちは、バッチサイズ、学習率、ウォームアップエポック数、モーメンタム係数、および重みづけ減衰のハイパーパラメータスイープを行った結果、当初のEfficientNet-B4実装に比べて性能を一切低下させることなく、6144のグローバルバッチサイズを達成できることを明らかにしました。このバッチサイズでは、検討したすべてのIPU-PODにおいて勾配蓄積数を高いまま維持できます。
性能結果
柔軟なハイパーパラメータ設定を使うことで、様々なIPU-PODシステムに対して高いスループットでEfficientNet-B4を学習できるようになりました。元々のEfficientNetの論文と同様に、350エポック分の学習を行います。『Making EfficientNet More Efficient(EfficientNetをより効率的にする)』では、EfficientNetファミリーのモデルをより低い解像度で事前学習してから、本来の解像度で微調整できることが実証されていますが、今回は他の実装と比較できるように、元の解像度を維持しました。
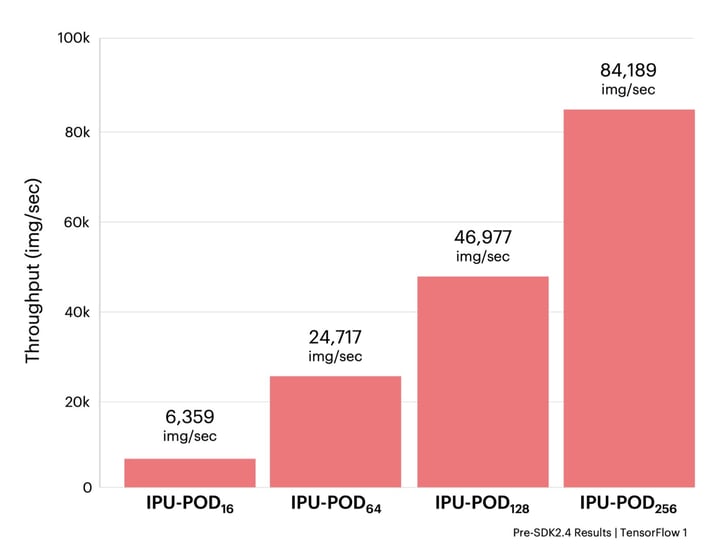
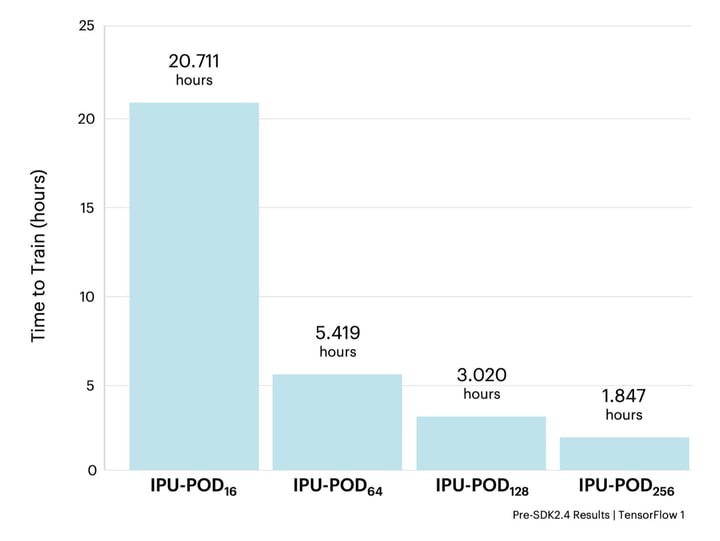
すべての実験において、IPU-PODのサイズに応じてレプリカ数と勾配蓄積数をスケーリングすることで、同じ基本的な機械学習のハイパーパラメータ構成を使用しました。その結果、82.54 ± 0.13%の検証精度でいずれも収束しました。
上記の結果から、主要なGPUハードウェアでの結果と対比して、IPUベースのシステムにおいてEfficientNetを学習させることがいかに高速化されるかがわかります。イノベーターが新しいアイデアを素早く反復・テストするためには、モデルを高速で学習することが不可欠です。その点、IPUベースのシステムではEfficientNet-B4を2時間以内に学習できるので、イノベーションのスピードを数日から数時間に短縮できます。
この高速化により、多くのコンピュータビジョンアプリケーションは、レガシーなプロセッサアーキテクチャの制約を受けることなく、大規模な学習を大幅に高速化できることが実証されました。EfficientNetのような次世代コンピュータビジョンモデルを、GraphcoreのIPU-PODシステムのような最新のハードウェアで使用すれば、CTスキャン解析やビデオアップスケーリングから故障診断、保険金請求の確認まで、ビジョン関連の膨大なユースケースを高速化できるでしょう。
これらの構成は現在、GraphcoreのGitHubサンプルで
お試しいただけます。(注:すべてのIPU-PODシステムの最新構成は、当社のPoplar SDK 2.4のリリースに伴い更新されます。)
この記事はTowards Data Scienceに掲載されたものです。
Towards Data Scienceの記事を読む
謝辞
この研究にご協力いただいたDominic Masters氏とCarlo Luschi氏に謝辞を述べるとともに、洞察を与えてくれたGraphcoreの同僚からの協力にも謝辞を述べます。