; ModuleID = 'start'
source_filename = "start"
target datalayout = "e-m:e-p270:32:32-p271:32:32-p272:64:64-i64:64-f80:128-n8:16:32:64-S128"
target triple = "x86_64-linux-gnu"
define void @_Z13_333___Pi_235() local_unnamed_addr #0 !dbg !35 {
top:
%0 = call i64 @get_vec_ptr_Pi(i32 0), !dbg !39
%1 = call i32 @get_vec_size_Pi(i32 0), !dbg !39
%2 = call i64 @get_vec_ptr_Pi(i32 1), !dbg !39
%3 = call i32 @get_vec_size_Pi(i32 1), !dbg !39
%4 = call i64 @get_vec_ptr_Pi(i32 2), !dbg !39
%5 = call i32 @get_vec_size_Pi(i32 2), !dbg !39
%6 = call i32 @llvm.colossus.get.scount.l(), !dbg !40
%coercion = inttoptr i64 %0 to i32*, !dbg !49
%pointerref = load i32, i32* %coercion, align 1, !dbg !49, !tbaa !61, !alias.scope !65, !noalias !68
%7 = call fastcc float @julia_pi_kernel_5874(i32 zeroext %pointerref), !dbg !60
%coercion1 = inttoptr i64 %2 to float*, !dbg !73
store float %7, float* %coercion1, align 1, !dbg !73, !tbaa !61, !alias.scope !65, !noalias !68
%8 = call i32 @llvm.colossus.get.scount.l(), !dbg !81
%9 = sub i32 %8, %6, !dbg !83
%coercion2 = inttoptr i64 %4 to i32*, !dbg !87
store i32 %9, i32* %coercion2, align 1, !dbg !87, !tbaa !61, !alias.scope !65, !noalias !68
ret void, !dbg !91
}
declare i64 @get_vec_ptr_Pi(i32) local_unnamed_addr
declare i32 @get_vec_size_Pi(i32) local_unnamed_addr
declare i32 @llvm.colossus.get.scount.l() local_unnamed_addr
define internal fastcc float @julia_pi_kernel_5874(i32 zeroext %0) unnamed_addr #0 !dbg !92 {
top:
%1 = mul i32 %0, 2917776, !dbg !93
%.not16 = icmp ult i32 %1, -2917775, !dbg !96
%value_phi.v = select i1 %.not16, i32 2917775, i32 -1, !dbg !101
%value_phi = add i32 %1, %value_phi.v, !dbg !101
%.not = icmp ugt i32 %1, %value_phi, !dbg !111
br i1 %.not, label %L78, label %L56, !dbg !95
L56: ; preds = %L56, %top
%value_phi4 = phi i32 [ %9, %L56 ], [ %1, %top ]
%value_phi6 = phi float [ %8, %L56 ], [ 0.000000e+00, %top ]
%2 = uitofp i32 %value_phi4 to float, !dbg !118
%3 = fadd float %2, 0xBFA99999A0000000, !dbg !132
%4 = fmul float %3, 0x3DF0000040000000, !dbg !134
%5 = fmul float %4, %4, !dbg !136
%6 = fadd float %5, 1.000000e+00, !dbg !141
%7 = fdiv float 4.000000e+00, %6, !dbg !144
%8 = fadd float %value_phi6, %7, !dbg !148
%.not15 = icmp eq i32 %value_phi4, %value_phi, !dbg !149
%9 = add i32 %value_phi4, 1, !dbg !151
br i1 %.not15, label %L78, label %L56, !dbg !152
L78: ; preds = %L56, %top
%value_phi10 = phi float [ 0.000000e+00, %top ], [ %8, %L56 ]
ret float %value_phi10, !dbg !153
}
attributes #0 = { "probe-stack"="inline-asm" }
!llvm.module.flags = !{!0, !1}
!llvm.dbg.cu = !{!2, !4, !5, !6, !7, !8, !9, !10, !11, !12, !13, !14, !15, !16, !17, !18, !19, !20, !21, !22, !23, !24, !25, !26, !27, !28, !29, !30, !31, !32, !33}
!julia.kernel = !{!34}
!0 = !{i32 2, !"Dwarf Version", i32 4}
!1 = !{i32 2, !"Debug Info Version", i32 3}
!2 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!3 = !DIFile(filename: "julia", directory: ".")
!4 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!5 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!6 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!7 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!8 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!9 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!10 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!11 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!12 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!13 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!14 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!15 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!16 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!17 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!18 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!19 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!20 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!21 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!22 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!23 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!24 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!25 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!26 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!27 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!28 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!29 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!30 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!31 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!32 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!33 = distinct !DICompileUnit(language: DW_LANG_Julia, file: !3, producer: "julia", isOptimized: true, runtimeVersion: 0, emissionKind: LineTablesOnly, nameTableKind: None)
!34 = !{void ()* @_Z13_333___Pi_235}
!35 = distinct !DISubprogram(name: "#333###Pi#235", linkageName: "julia_#333###Pi#235_5871", scope: null, file: !36, line: 68, type: !37, scopeLine: 68, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!36 = !DIFile(filename: "/home/cceamgi/.julia/packages/IPUToolkit/1u83e/src/compiler/codelet.jl#@#==#892eee7a-73be-4479-8d00-6e1ee8bdd97b", directory: ".")
!37 = !DISubroutineType(types: !38)
!38 = !{}
!39 = !DILocation(line: 69, scope: !35)
!40 = !DILocation(line: 45, scope: !41, inlinedAt: !43)
!41 = distinct !DISubprogram(name: "get_scount_l;", linkageName: "get_scount_l", scope: !42, file: !42, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!42 = !DIFile(filename: "/home/cceamgi/.julia/packages/IPUToolkit/1u83e/src/compiler/runtime.jl", directory: ".")
!43 = !DILocation(line: 100, scope: !44, inlinedAt: !46)
!44 = distinct !DISubprogram(name: "macro expansion;", linkageName: "macro expansion", scope: !45, file: !45, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!45 = !DIFile(filename: "/home/cceamgi/.julia/packages/IPUToolkit/1u83e/src/compiler/timing.jl#@#==#892eee7a-73be-4479-8d00-6e1ee8bdd97b", directory: ".")
!46 = !DILocation(line: 35, scope: !47, inlinedAt: !39)
!47 = distinct !DISubprogram(name: "Pi;", linkageName: "Pi", scope: !48, file: !48, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!48 = !DIFile(filename: "/home/cceamgi/repo/rsdg-meetings/2023-07-20-julia-ipu/julia-ipu.jl#==#892eee7a-73be-4479-8d00-6e1ee8bdd97b", directory: ".")
!49 = !DILocation(line: 119, scope: !50, inlinedAt: !52)
!50 = distinct !DISubprogram(name: "unsafe_load;", linkageName: "unsafe_load", scope: !51, file: !51, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!51 = !DIFile(filename: "pointer.jl", directory: ".")
!52 = !DILocation(line: 46, scope: !53, inlinedAt: !55)
!53 = distinct !DISubprogram(name: "getindex;", linkageName: "getindex", scope: !54, file: !54, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!54 = !DIFile(filename: "/home/cceamgi/.julia/packages/IPUToolkit/1u83e/src/compiler/vertices.jl", directory: ".")
!55 = !DILocation(line: 1336, scope: !56, inlinedAt: !58)
!56 = distinct !DISubprogram(name: "_getindex;", linkageName: "_getindex", scope: !57, file: !57, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!57 = !DIFile(filename: "abstractarray.jl", directory: ".")
!58 = !DILocation(line: 1286, scope: !59, inlinedAt: !60)
!59 = distinct !DISubprogram(name: "getindex;", linkageName: "getindex", scope: !57, file: !57, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!60 = !DILocation(line: 101, scope: !44, inlinedAt: !46)
!61 = !{!62, !62, i64 0}
!62 = !{!"jtbaa_data", !63, i64 0}
!63 = !{!"jtbaa", !64, i64 0}
!64 = !{!"jtbaa"}
!65 = !{!66}
!66 = !{!"jnoalias_data", !67}
!67 = !{!"jnoalias"}
!68 = !{!69, !70, !71, !72}
!69 = !{!"jnoalias_gcframe", !67}
!70 = !{!"jnoalias_stack", !67}
!71 = !{!"jnoalias_typemd", !67}
!72 = !{!"jnoalias_const", !67}
!73 = !DILocation(line: 146, scope: !74, inlinedAt: !75)
!74 = distinct !DISubprogram(name: "unsafe_store!;", linkageName: "unsafe_store!", scope: !51, file: !51, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!75 = !DILocation(line: 42, scope: !76, inlinedAt: !77)
!76 = distinct !DISubprogram(name: "setindex!;", linkageName: "setindex!", scope: !54, file: !54, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!77 = !DILocation(line: 1419, scope: !78, inlinedAt: !79)
!78 = distinct !DISubprogram(name: "_setindex!;", linkageName: "_setindex!", scope: !57, file: !57, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!79 = !DILocation(line: 1389, scope: !80, inlinedAt: !60)
!80 = distinct !DISubprogram(name: "setindex!;", linkageName: "setindex!", scope: !57, file: !57, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!81 = !DILocation(line: 45, scope: !41, inlinedAt: !82)
!82 = !DILocation(line: 102, scope: !44, inlinedAt: !46)
!83 = !DILocation(line: 86, scope: !84, inlinedAt: !86)
!84 = distinct !DISubprogram(name: "-;", linkageName: "-", scope: !85, file: !85, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !2, retainedNodes: !38)
!85 = !DIFile(filename: "int.jl", directory: ".")
!86 = !DILocation(line: 103, scope: !44, inlinedAt: !46)
!87 = !DILocation(line: 146, scope: !74, inlinedAt: !88)
!88 = !DILocation(line: 42, scope: !76, inlinedAt: !89)
!89 = !DILocation(line: 1419, scope: !78, inlinedAt: !90)
!90 = !DILocation(line: 1389, scope: !80, inlinedAt: !46)
!91 = !DILocation(line: 70, scope: !35)
!92 = distinct !DISubprogram(name: "pi_kernel", linkageName: "julia_pi_kernel_5874", scope: null, file: !48, line: 21, type: !37, scopeLine: 21, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!93 = !DILocation(line: 88, scope: !94, inlinedAt: !95)
!94 = distinct !DISubprogram(name: "*;", linkageName: "*", scope: !85, file: !85, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!95 = !DILocation(line: 23, scope: !92)
!96 = !DILocation(line: 513, scope: !97, inlinedAt: !98)
!97 = distinct !DISubprogram(name: "<;", linkageName: "<", scope: !85, file: !85, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!98 = !DILocation(line: 376, scope: !99, inlinedAt: !101)
!99 = distinct !DISubprogram(name: ">;", linkageName: ">", scope: !100, file: !100, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!100 = !DIFile(filename: "operators.jl", directory: ".")
!101 = !DILocation(line: 343, scope: !102, inlinedAt: !104)
!102 = distinct !DISubprogram(name: "steprange_last;", linkageName: "steprange_last", scope: !103, file: !103, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!103 = !DIFile(filename: "range.jl", directory: ".")
!104 = !DILocation(line: 325, scope: !105, inlinedAt: !106)
!105 = distinct !DISubprogram(name: "StepRange;", linkageName: "StepRange", scope: !103, file: !103, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!106 = !DILocation(line: 379, scope: !105, inlinedAt: !107)
!107 = !DILocation(line: 24, scope: !108, inlinedAt: !109)
!108 = distinct !DISubprogram(name: "_colon;", linkageName: "_colon", scope: !103, file: !103, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!109 = !DILocation(line: 22, scope: !110, inlinedAt: !95)
!110 = distinct !DISubprogram(name: "Colon;", linkageName: "Colon", scope: !103, file: !103, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!111 = !DILocation(line: 38, scope: !112, inlinedAt: !114)
!112 = distinct !DISubprogram(name: "&;", linkageName: "&", scope: !113, file: !113, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!113 = !DIFile(filename: "bool.jl", directory: ".")
!114 = !DILocation(line: 669, scope: !115, inlinedAt: !116)
!115 = distinct !DISubprogram(name: "isempty;", linkageName: "isempty", scope: !103, file: !103, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!116 = !DILocation(line: 897, scope: !117, inlinedAt: !95)
!117 = distinct !DISubprogram(name: "iterate;", linkageName: "iterate", scope: !103, file: !103, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!118 = !DILocation(line: 165, scope: !119, inlinedAt: !121)
!119 = distinct !DISubprogram(name: "Float32;", linkageName: "Float32", scope: !120, file: !120, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!120 = !DIFile(filename: "float.jl", directory: ".")
!121 = !DILocation(line: 7, scope: !122, inlinedAt: !124)
!122 = distinct !DISubprogram(name: "convert;", linkageName: "convert", scope: !123, file: !123, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!123 = !DIFile(filename: "number.jl", directory: ".")
!124 = !DILocation(line: 370, scope: !125, inlinedAt: !127)
!125 = distinct !DISubprogram(name: "_promote;", linkageName: "_promote", scope: !126, file: !126, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!126 = !DIFile(filename: "promotion.jl", directory: ".")
!127 = !DILocation(line: 393, scope: !128, inlinedAt: !129)
!128 = distinct !DISubprogram(name: "promote;", linkageName: "promote", scope: !126, file: !126, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!129 = !DILocation(line: 422, scope: !130, inlinedAt: !131)
!130 = distinct !DISubprogram(name: "+;", linkageName: "+", scope: !126, file: !126, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!131 = !DILocation(line: 25, scope: !92)
!132 = !DILocation(line: 410, scope: !133, inlinedAt: !131)
!133 = distinct !DISubprogram(name: "-;", linkageName: "-", scope: !120, file: !120, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!134 = !DILocation(line: 411, scope: !135, inlinedAt: !131)
!135 = distinct !DISubprogram(name: "*;", linkageName: "*", scope: !120, file: !120, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!136 = !DILocation(line: 411, scope: !135, inlinedAt: !137)
!137 = !DILocation(line: 332, scope: !138, inlinedAt: !140)
!138 = distinct !DISubprogram(name: "literal_pow;", linkageName: "literal_pow", scope: !139, file: !139, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!139 = !DIFile(filename: "intfuncs.jl", directory: ".")
!140 = !DILocation(line: 26, scope: !92)
!141 = !DILocation(line: 409, scope: !142, inlinedAt: !143)
!142 = distinct !DISubprogram(name: "+;", linkageName: "+", scope: !120, file: !120, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!143 = !DILocation(line: 422, scope: !130, inlinedAt: !140)
!144 = !DILocation(line: 412, scope: !145, inlinedAt: !146)
!145 = distinct !DISubprogram(name: "/;", linkageName: "/", scope: !120, file: !120, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!146 = !DILocation(line: 425, scope: !147, inlinedAt: !140)
!147 = distinct !DISubprogram(name: "/;", linkageName: "/", scope: !126, file: !126, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!148 = !DILocation(line: 409, scope: !142, inlinedAt: !140)
!149 = !DILocation(line: 521, scope: !150, inlinedAt: !151)
!150 = distinct !DISubprogram(name: "==;", linkageName: "==", scope: !126, file: !126, type: !37, spFlags: DISPFlagDefinition | DISPFlagOptimized, unit: !4, retainedNodes: !38)
!151 = !DILocation(line: 901, scope: !117, inlinedAt: !152)
!152 = !DILocation(line: 28, scope: !92)
!153 = !DILocation(line: 29, scope: !92)
Conclusions 🎉
.png?width=1440&name=Julia%20header%20(1).png "Julia header (1)")

.png?width=902&height=370&name=LysTgpt%20(1).png)
.png?width=1103&height=610&name=LLVM%20(1).png)
 Common choices are
Common choices are 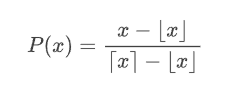 In the following we'll always talk about the latter probability function
In the following we'll always talk about the latter probability function 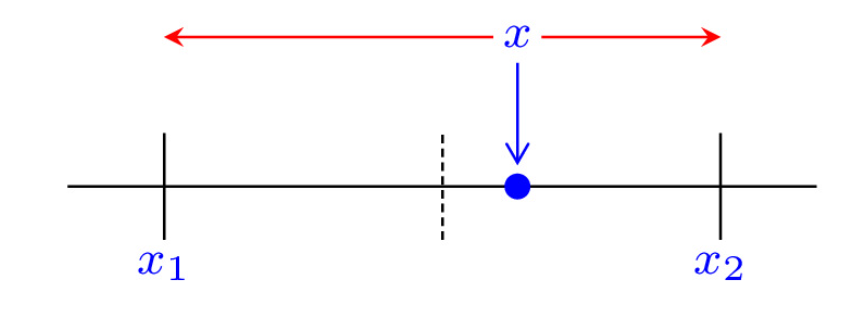 (source: "What Is Stochastic Rounding?" by Nick Higham)
(source: "What Is Stochastic Rounding?" by Nick Higham)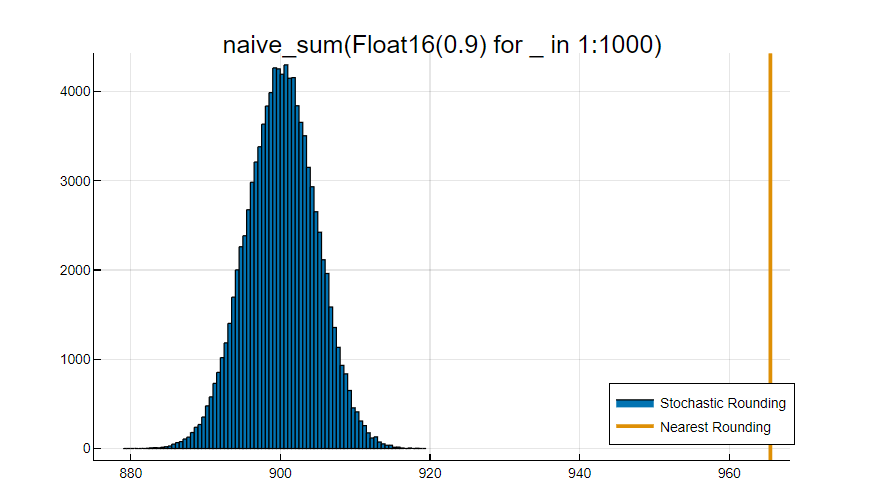

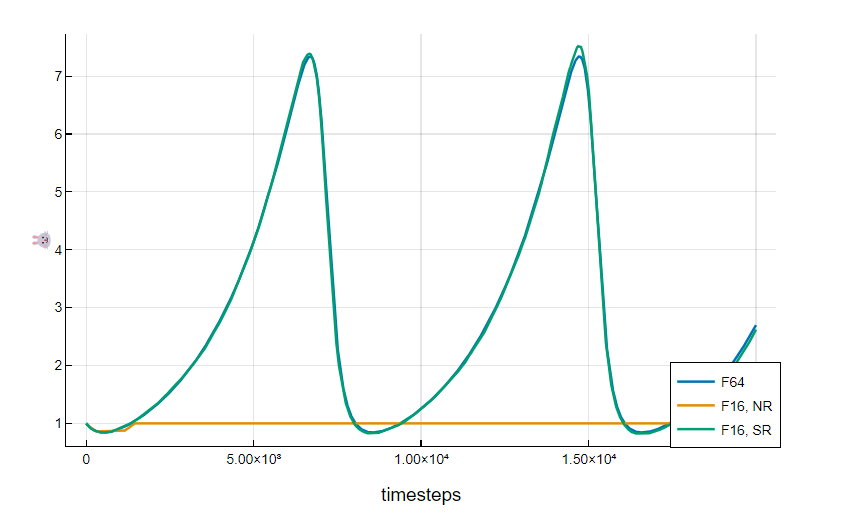 Automatic differentiation
Automatic differentiation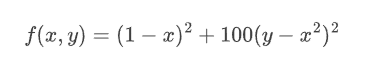
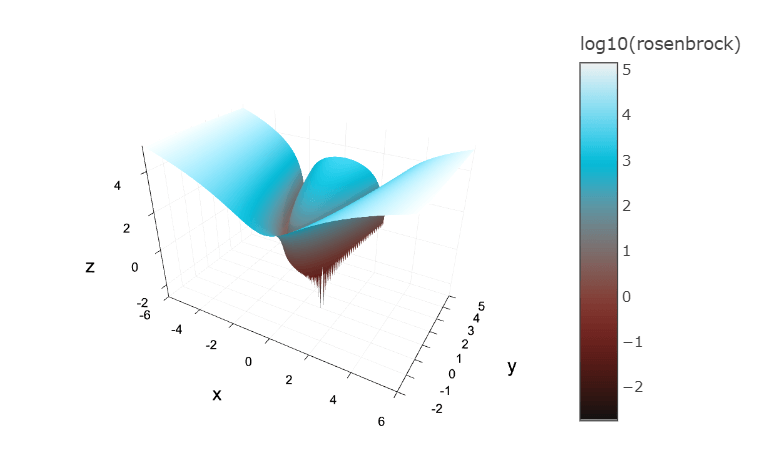
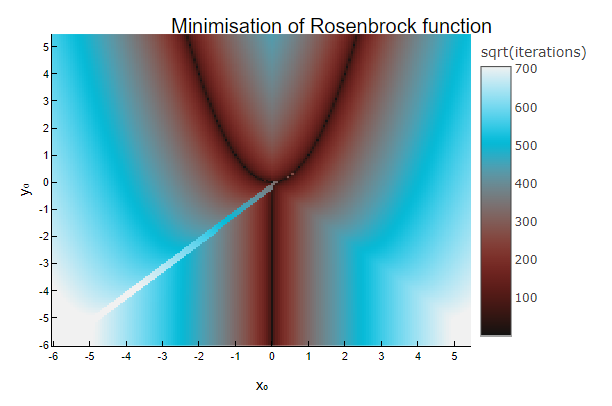
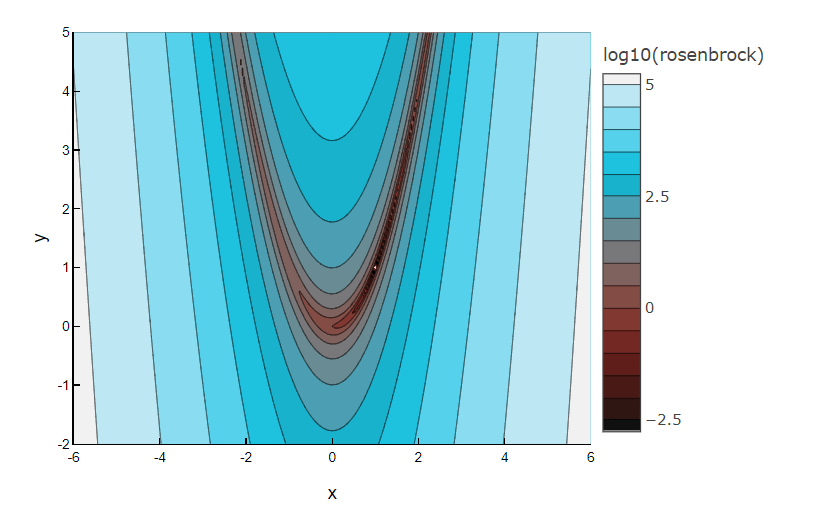 Finding the valley is trivial, but converging to the global minimum is hard.
Finding the valley is trivial, but converging to the global minimum is hard.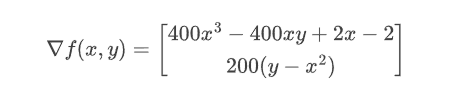 We can ask Enzyme to compute the partial derivative on the second argument:
We can ask Enzyme to compute the partial derivative on the second argument: