Oct 04, 2022
Oct 04, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamWe are pleased to announce the release of Poplar SDK 3.0—further enhancing ease of use and improving the developer experience.
Poplar SDK 3.0 is now available for download from Graphcore’s support portal and Docker Hub where you can find our growing range of Poplar containers.
We have also refreshed the design and functionality of the Graphcore Model Garden—while adding several new model examples spanning multiple application domains—and have further expanded our developer resources by publishing new user guides and tutorials.
A brief summary of the Poplar SDK 3.0 release is provided below; for a more complete list of updates, please see the release notes.
In response to customer feedback and to provide a more flexible and easy to use PyTorch development experience, the PyTorch dispatcher is now used as the default frontend for building static graph representations of a torch.nn.Module.
Previous releases used, torch.jit.trace by default; however, the new dispatcher overcomes several limitations of this approach: specifically, only tensors could be passed as arguments, models were required to run once on the CPU as part of the tracing process, and source code location was not supported.
Using the PyTorch dispatcher by default provides many benefits, including improved performance and greatly simplified handling of float16 operations—in addition to the ability to pass Python primitives and a broader range of arguments. The PyTorch dispatcher frontend is supported on most platforms, meaning no special changes are required to use it.
The Poplar SDK 3.0 update introduces several new features that broaden the range of inference deployment choices on offer. From the standpoint of general ease of use and seamless integration into the broader machine learning ecosystem, TensorFlow Serving and Poplar Triton backend provide “ready-to-run” implementations, while the Model Runtime library (for which we are publishing the API with this release) will suit users looking for complete flexibility.
The Poplar SDK 3.0 release includes full support (previously in preview) for serving models on the IPU using the open-source Triton Inference Server, allowing users to deploy inference models more easily.
Models written using PyTorch for the IPU, PopART and TensorFlow for the IPU can be compiled and saved in PopEF (Poplar Exchange Format) format, which can then be served by the Poplar Triton backend.
For more details, see the updated Poplar Triton backend user guide; additionally, a PyTorch inference example can be found here.
The Graphcore distribution of TensorFlow Serving is now fully supported, having previously been in preview.
TensorFlow Serving is an alternative to the Poplar Triton backend (detailed above) and enables easy, high-performance and low-latency serving of machine learning models. This distribution will allow users to export a precompiled model to the standard SavedModel format, enabling later deployment for inference using the Graphcore distribution of TensorFlow Serving.
To coincide with the release of SDK 3.0 we have published a short introductory blog post showing how simple it can be to create, train, export and serve a model within minutes using TensorFlow Serving for IPU.
User guides for the Graphcore distribution of TensorFlow Serving 2 and TensorFlow Serving 1 are available on the Graphcore documentation portal. We have also published examples for TensorFlow 2 and TensorFlow 1 to help you get started.
You can read more about TensorFlow Serving in our dedicated blog.
With this release we are publishing the API documentation for the Model Runtime library, which allows users to easily load and run a model stored in the Poplar Exchange Format (PopEF) on the IPU in their own inference harness. It is a tool that is used by our Poplar Triton backend, but we are pleased to be releasing it for external use.
Model Runtime supports C++ and Python and is divided into two parts: a high-level API allowing quick model deployment and requiring minimal familiarity with Poplar SDK libraries and IPU hardware, and a low-level API aimed at advanced users, which allows more flexibility and control for workload deployments.
Full documentation for the model runtime library, including several examples, can be found here.
Previously an experimental feature, Graphcore automatic loss scaling (ALS) is now in preview for PyTorch and PopART.
Graphcore ALS uses a unique histogram-based loss scaling algorithm to reliably and easily improve stability when training large models in mixed precision. This yields a combination of efficiency, ease of use, and remarkable stability surpassing all other loss scaling methods.
While the approach behind Graphcore ALS is technically accelerator-agnostic and should benefit anyone training large models in mixed precision, its origin lies in our unique experiences developing applications for IPUs.
To learn more about Graphcore ALS, visit our dedicated blog post.
In response to customer demand, Poplar SDK 3.0 includes full support for the Red Hat Linux 8 operating system.
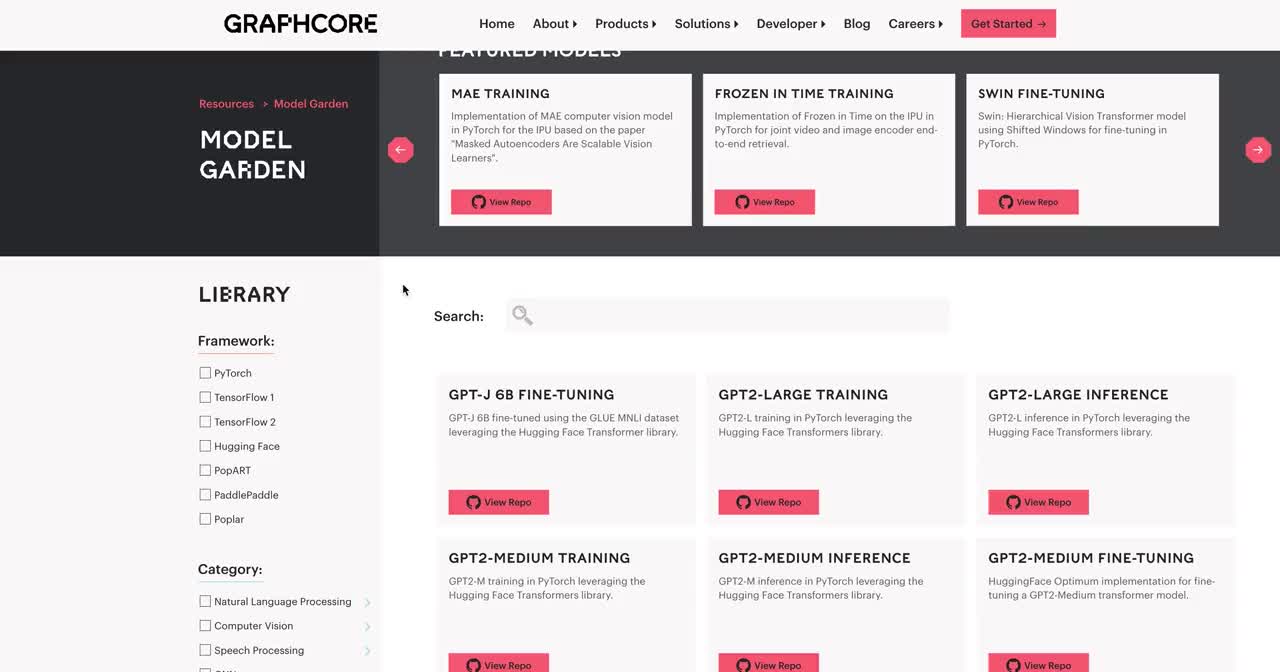
Graphcore’s Model Garden—a repository of IPU-ready ML applications including computer vision, NLP, graph neural networks and more—is a stand-out resource that has proved popular with developers looking to easily browse, filter and access reproducible code.
A major update to the Model Garden this month included a design refresh and several functionality improvements aiming to make it even easier for developers to find specific models for their needs. Developers can now search and filter by specific ML tasks, such as text generation, text-to-image, question answering, object detection, image classification, and many more.
As always, we have continued to update the content of our Model Garden and associated GitHub repositories. Since the release of the previous Poplar SDK version in July, a number of new models and public examples have been made available spanning several application domains, as detailed below.
MAE – training (PyTorch)
Swin – fine-tuning (PyTorch)
Frozen in Time – training (PyTorch)
Benchmark performance results for many models in our Model Garden across multiple frameworks and multiple platforms are updated for SDK 3.0 and published on the Performance Results page of our website.
In addition to the highlights, features, and additions to the Model Garden and public examples detailed above, the following developer resources have been created or updated between the release of Poplar SDK versions 2.6 and 3.0:
Share: