
Aug 10, 2022
Aug 10, 2022
We're Hiring
Join us and build the next generation AI stack - including silicon, hardware and software - the worldwide standard for AI compute
Join our teamPaperspace is an industry-leading MLOPs platform specialising in on-demand high-performance computing. Thanks to a new partnership with Graphcore, any Paperspace user can now quickly access Intelligent Processing Unit (IPU) technology within seconds in a web browser via Gradient Notebooks, a web-based Jupyter IDE.
This blog post will walk you through a few simple steps to get up and running with Graphcore IPUs on Paperspace. We will show you how to train your first model, using one of our HuggingFace Optimum vision transformer (ViT) notebooks as an example. We will also guide you through other features of Paperspace Gradient Notebooks so you can run more tutorials and start building your own models for IPU.
To learn more about Graphcore’s partnership with Paperspace, you can check out our announcement here or visit Paperspace's dedicated page for IPU here.
First, you need to ensure that you have created an account in Paperspace. This is a one-click process, and gives you instant access to preconfigured IPU-optimised runtimes—all without having to worry about development environment setup. You will now have access to an unlimited number of six-hour sessions with a Graphcore IPU-POD16 Classic, which is composed of 4 IPU-M2000 systems for a total of 16 IPU chips.
The IPU is a completely new kind of massively parallel processor specifically designed for AI and machine learning applications. Each IPU has 1,472 powerful processor cores, running nearly 9,000 independent parallel program threads. The IPU-POD16 Classic system available on Paperspace gives you access to 4 petaFLOPS of AI compute, making it the most powerful free AI hardware available on the platform.
Once you’ve signed in, click the Create a project button on your workspace. The project lets you access various MLOps features, and most importantly lets you spin up a Gradient Notebook. The IDE handles provisioning a VM and setting up of the docker container, Poplar SDK, and code repository.
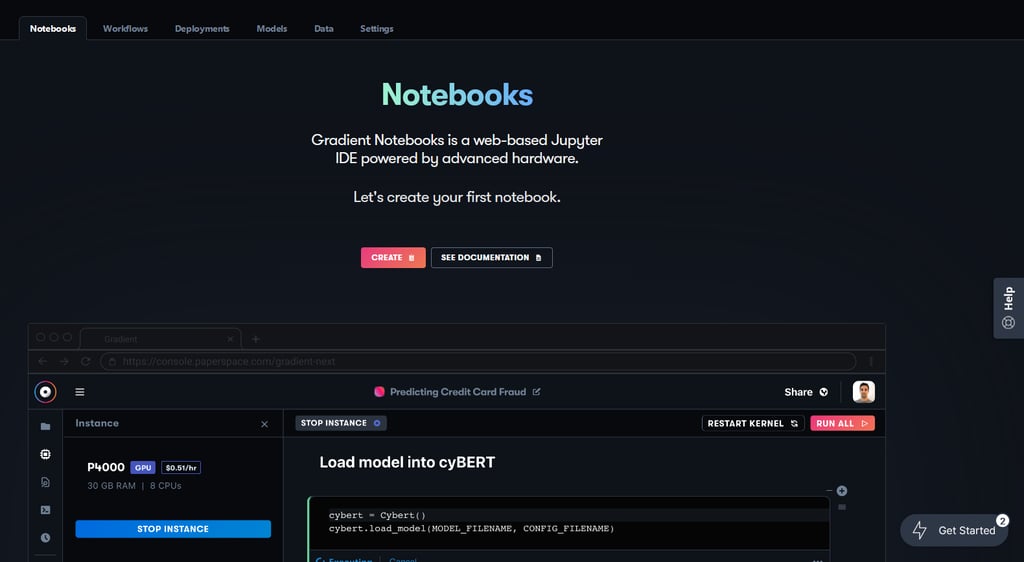 In the notebook creation view, you will see the option to run one of several IPU-optimised runtimes, such as Hugging Face Optimum, PyTorch, and TensorFlow 2 IPU Experience. Starting the notebook loads the pre-configured container and notebooks, and takes care of everything under the hood so you can jump straight to running the code.
In the notebook creation view, you will see the option to run one of several IPU-optimised runtimes, such as Hugging Face Optimum, PyTorch, and TensorFlow 2 IPU Experience. Starting the notebook loads the pre-configured container and notebooks, and takes care of everything under the hood so you can jump straight to running the code.
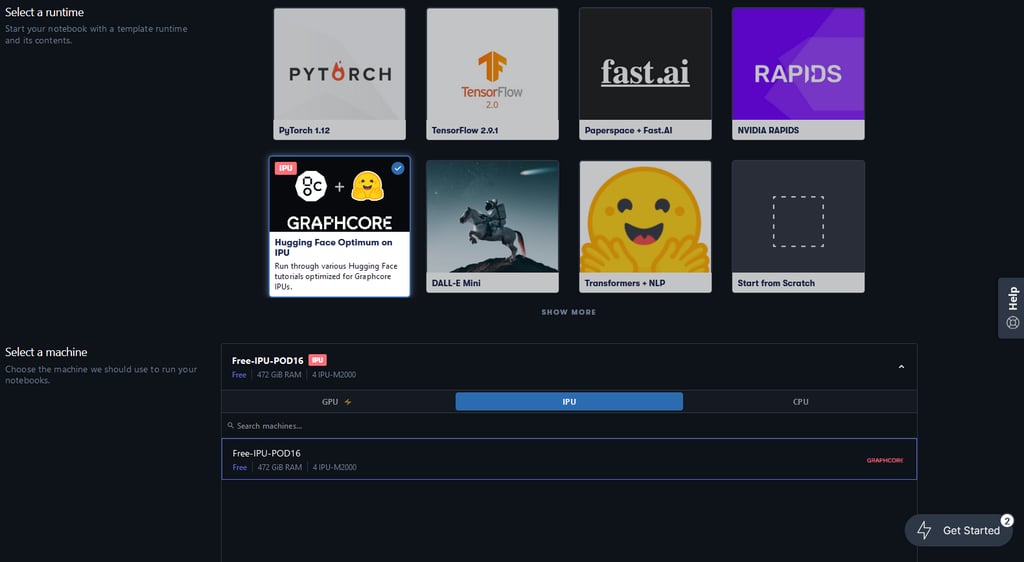 In this case, we will select the Hugging Face Optimum on IPU runtime. This runtime uses a PyTorch-Jupyter container from the official Graphcore Docker Hub, ensuring that the Poplar SDK and PyTorch libraries are pre-installed and compatible with the IPU system in Paperspace. The runtime also loads a curated repo of notebooks, and takes care of various environment and data configuration to optimise ease of use and let you focus on learning about IPUs and model development.
In this case, we will select the Hugging Face Optimum on IPU runtime. This runtime uses a PyTorch-Jupyter container from the official Graphcore Docker Hub, ensuring that the Poplar SDK and PyTorch libraries are pre-installed and compatible with the IPU system in Paperspace. The runtime also loads a curated repo of notebooks, and takes care of various environment and data configuration to optimise ease of use and let you focus on learning about IPUs and model development.
It will take a few minutes to spin-up the virtual machine. Once it’s done, expand the get-started folder and open the ViT walkthrough training notebook. You can follow the notebook step by step as it takes you through the data processing, training, and evaluation of the ViT model. We’ll cover some highlights of what you can do with this notebook in Gradient.
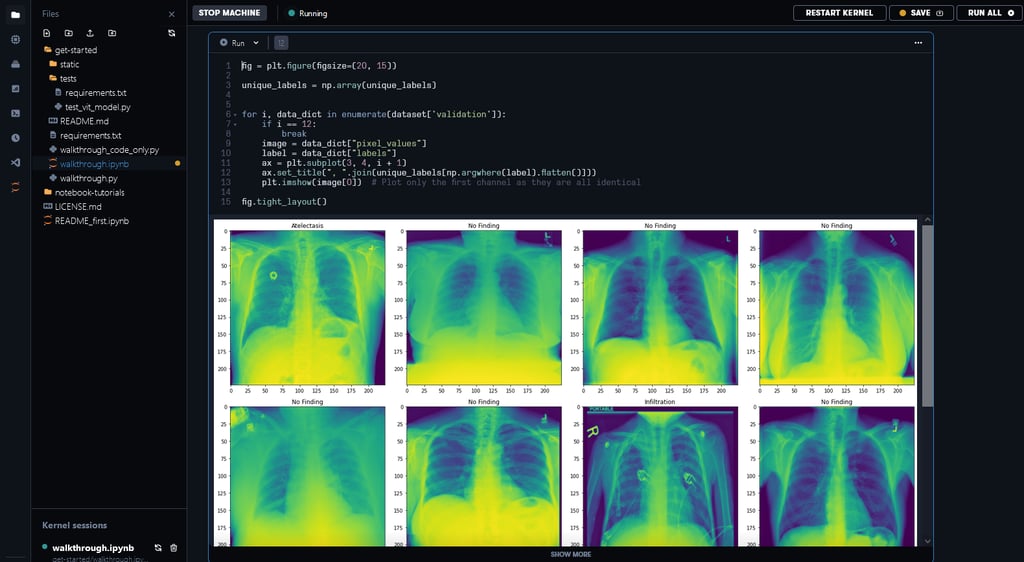
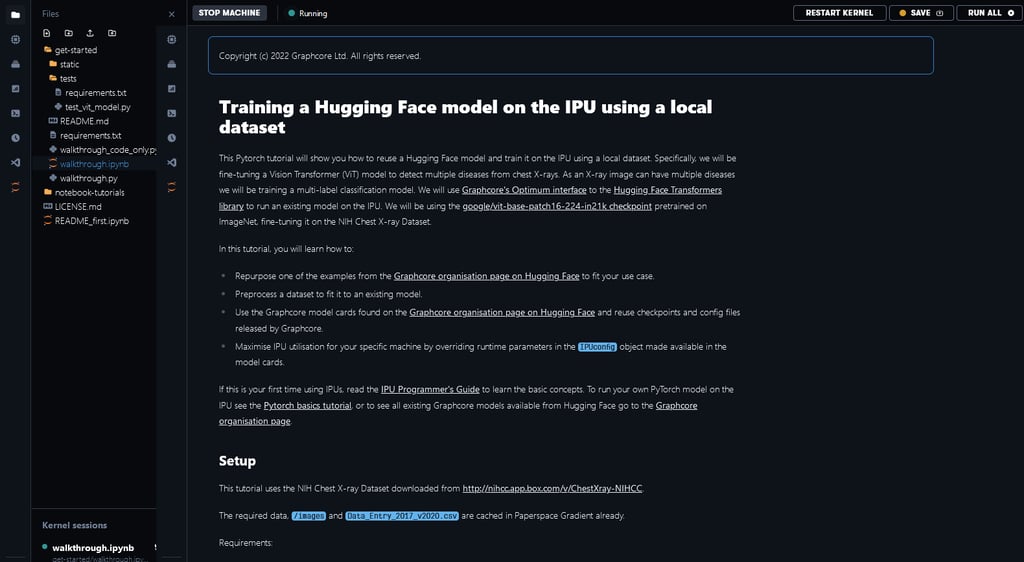 The notebook we’re using as a demonstration will show you how to pre-process a large, widely used chest x-ray dataset and run a ViT model in HuggingFace Optimum on this dataset. This is a good example of the type of workflow you’ll commonly encounter when developing your own models using IPUs and Hugging Face Optimum. For a bit more context about this specific ViT implementation (and ViT models in general), check out this deep dive on running ViT in Hugging Face Optimum Graphcore.
The notebook we’re using as a demonstration will show you how to pre-process a large, widely used chest x-ray dataset and run a ViT model in HuggingFace Optimum on this dataset. This is a good example of the type of workflow you’ll commonly encounter when developing your own models using IPUs and Hugging Face Optimum. For a bit more context about this specific ViT implementation (and ViT models in general), check out this deep dive on running ViT in Hugging Face Optimum Graphcore.
In order to run the ViT Notebook, you won’t need to download the chest x-ray dataset: we have made it available in /graphcore/chest-xray-nihcc alongside other useful datasets and precompiled executables used in the runtimes at /graphcore. The data folder is accessible in all IPU runtimes.
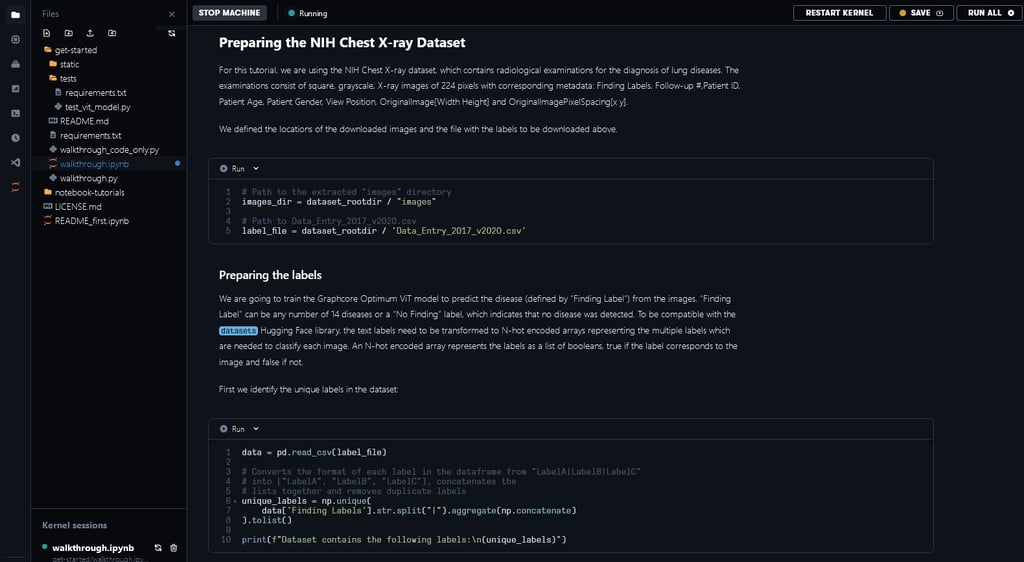
Paperspace Gradient is a supercharged MLOps platform that lets you go through the model development and deployment lifecycle faster. One of its most important features is its data store. When running your code that requires generating or downloading large data, we recommend that you store it in the /tmp folder so as not to fill your local data storage limits.
Running an IPU in Gradient gives you an initial 10GB of data storage in the free tier (5GB more than other runtimes), with the option to get more free storage. Additionally, a range of other storage options are provided for users on Gradient’s paid plans. If you need permanent and shareable storage, you can use high performance data storage through Paperspace Datasets, which lets you keep and access data across all the runtimes in your project.
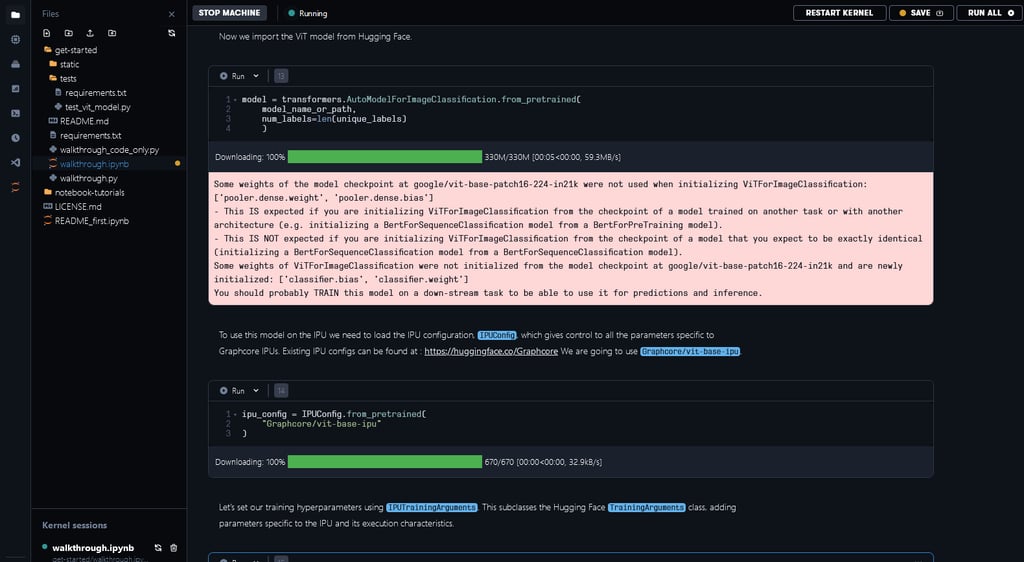
To train the ViT model on the IPU we need to use the IPUTrainer, which takes the same arguments as the original Transformer Trainer, in tandem with the IPUConfig object which specifies the behaviour for compilation and execution on the IPU. Running through the notebook will include downloading the IPUConfig made available through the Graphcore/vit-base-ipu, using the pre-trained vit checkpoints model card found in google/vit-base-patch16-224-in21k,and fine-tuning it using the Chest Xray Dataset. This lets you run your training in IPUs using optimised runtime configurations.
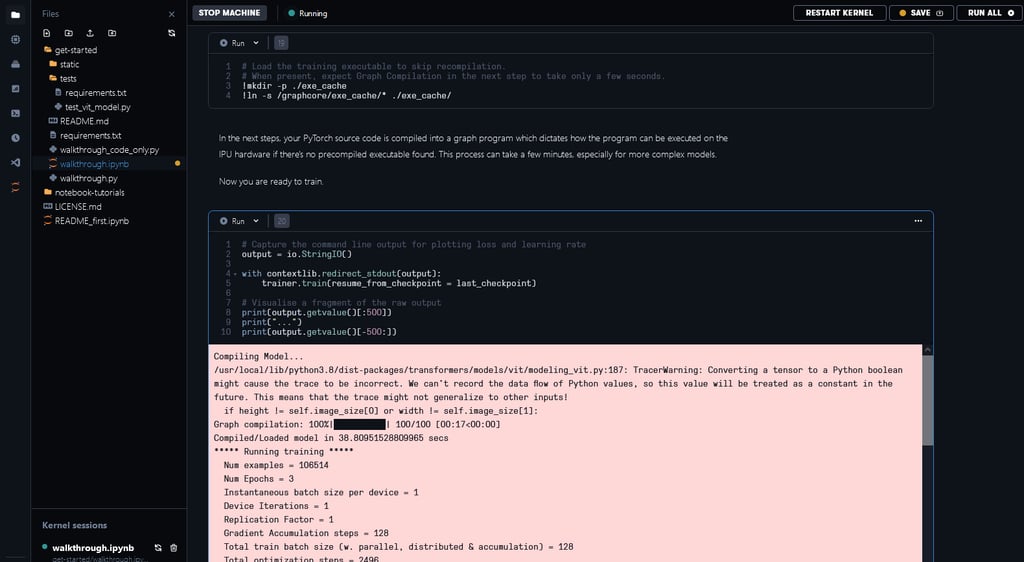
 The PyTorch source code is compiled into a graph program which dictates how the program can be executed on the IPU hardware. The time to perform this compilation step would depend on the model complexity.
The PyTorch source code is compiled into a graph program which dictates how the program can be executed on the IPU hardware. The time to perform this compilation step would depend on the model complexity.
In order to save time, a pre-compiled execution graph can be loaded so the model doesn't need to be recompiled. You can see the documentation on Precompilation and caching to know how it works.
We’ve made executable files available for some of the configurations in our notebook examples in Paperspace. This step can take a few minutes without the pre-compilation files or when it’s necessary to recompile because of changes in the model.
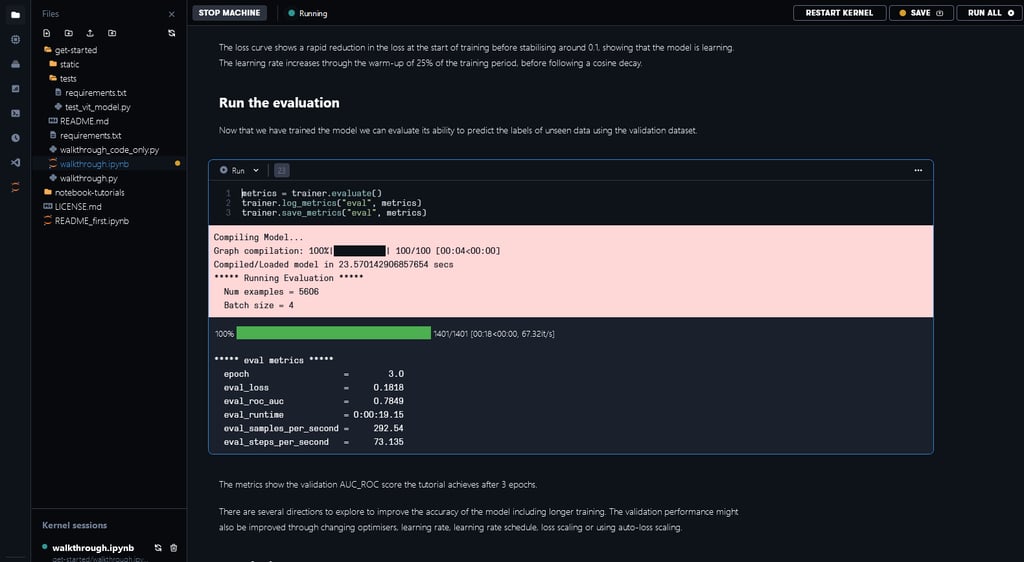
 We have implemented a custom metric for the area under the ROC (receiver operating characteristic) curve (AUC_ROC). It is a commonly used performance metric for multi-label classification tasks because it is insensitive to class imbalance and easy to interpret. After completing training and evaluation, you can see the validation AUC_ROC score across 3 epochs to be 0.7811 for this 14-category multi-label classification task.
We have implemented a custom metric for the area under the ROC (receiver operating characteristic) curve (AUC_ROC). It is a commonly used performance metric for multi-label classification tasks because it is insensitive to class imbalance and easy to interpret. After completing training and evaluation, you can see the validation AUC_ROC score across 3 epochs to be 0.7811 for this 14-category multi-label classification task.
Now that you have been able to run your first Notebook in Paperspace Gradient, you are free to click Advanced options to see the pre-loaded configuration and modify it for your own use.
Looking at the Hugging Face Optimum runtime, you can see through the advanced options that it is configured to load the gradient-ai/Graphcore-Huggingface repo and run it with a PyTorch docker container from Graphcore Docker Hub containing all the necessary libraries and Poplar SDK.
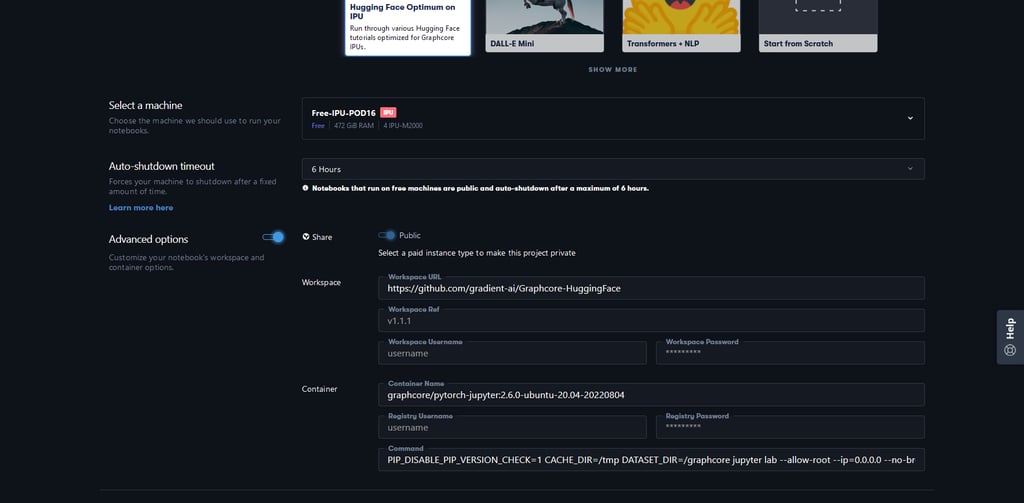
You can easily modify the runtime’s advanced options in order to load your own repository, and run it in a different Docker Image combination. This example shows how you can change the repository field to use the Graphcore Application Examples repo and select a TensorFlow 1 Image from Graphcore’s official Docker Hub releases.
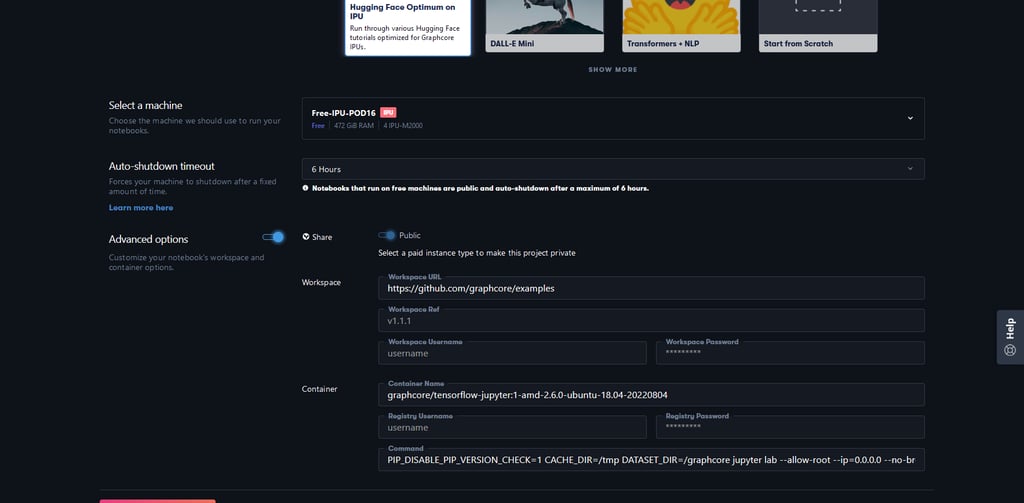 Do note that when setting the advanced options manually, you need to match the IPU host server OS (in this case, AMD) to the correct Docker OS tags (tf1-amd).
Do note that when setting the advanced options manually, you need to match the IPU host server OS (in this case, AMD) to the correct Docker OS tags (tf1-amd).
This should let you run any TensorFlow 1 code from the Graphcore Application Examples repo in this Notebook IDE.
While Gradient Notebooks focuses on providing a notebook-style interface, it is a complete IDE with access to the terminal. This powerful feature lets you run the rest of the scripts made available in Graphcore’s examples and tutorials.
Click on the terminal icon to launch a shell interface. From there, you can type away to replicate one of Graphcore’s published benchmarks or run our tutorials.
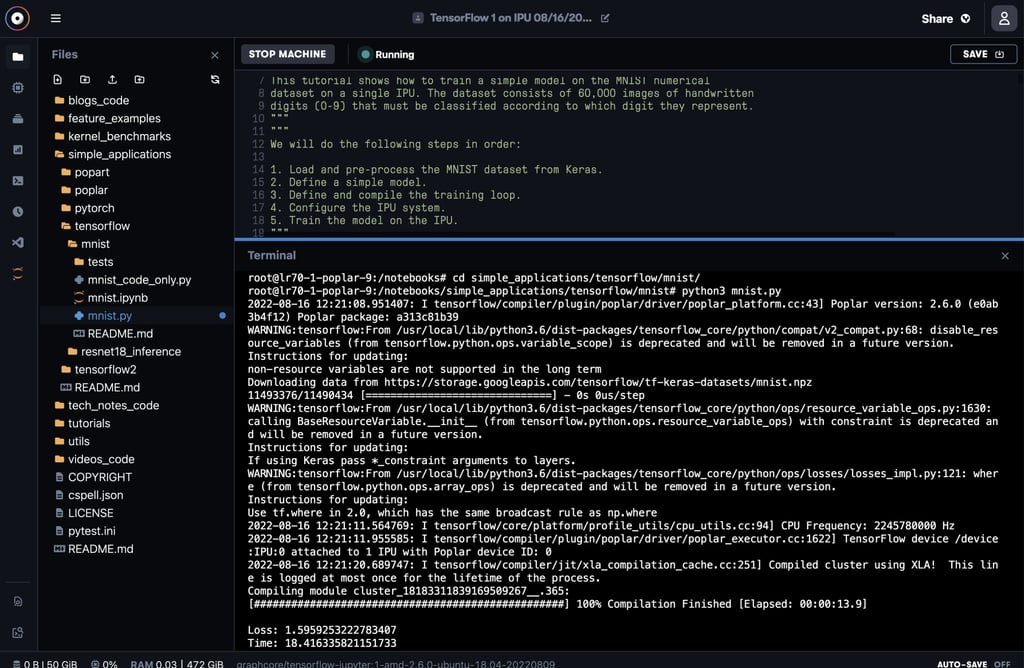
Now that you’ve managed to run your first few notebooks, you can go through some of our other tutorials to learn more about how to develop in IPUs.
Share:

