Jun 30, 2021 \ AI, Corporate, Benchmarks
Jun 30, 2021 \ AI, Corporate, Benchmarks
공유:
Graphcore는 AI 업계에서 가장 널리 인정 받는 비교 벤치마킹 프로세스인 MLPerfTM에 사상 최초로 훈련 결과를 제출하고 탁월한 훈련 성능 결과를 공개하게 되어 기쁘게 생각합니다.
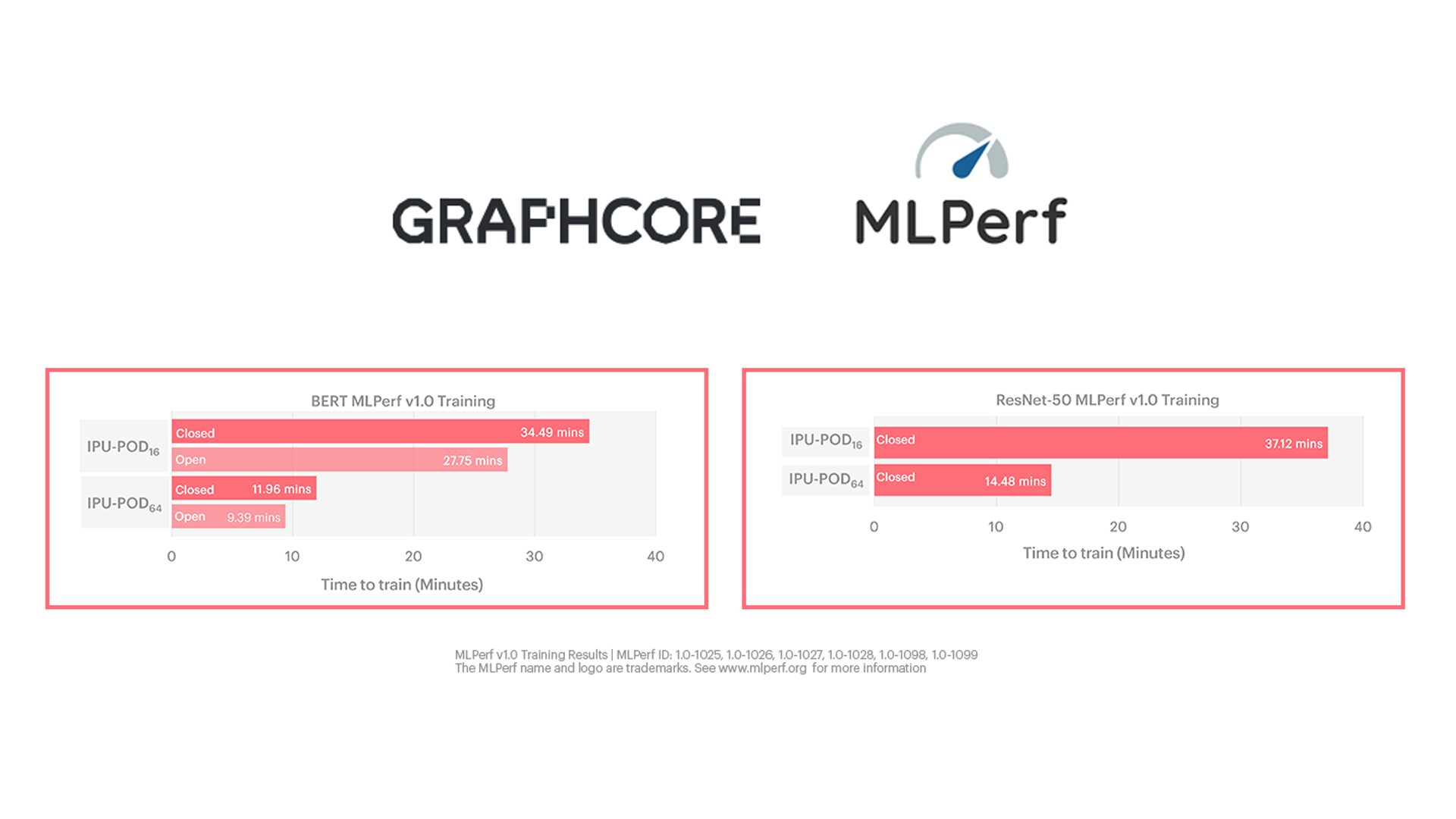
Graphcore는 IPU-POD64의 9분이 조금 넘는 BERT 훈련 소요 시간과 14.5분의 ResNet-50 훈련 소요 시간 등 탁월한 결과를 창출했습니다. 이는 슈퍼컴퓨터 수준의 AI 성능에 해당합니다.
또한 MLPerf 결과, Graphcore의 시판 시스템은 최신 NVIDIA보다 달러당 지표가 더 우수한 것으로 나타나 시장의 선두주자로 확실하게 자리매김했습니다.
이를 통해 Graphcore는 제3자를 통해 자사의 시스템이 차세대 AI뿐 아니라 오늘날 가장 널리 사용되는 애플리케이션에서도 훨씬 더 우수하다는 사실을 고객들에게 입증해 보였습니다.
이제 성숙한 소프트웨어 스택, 혁신적인 아키텍처와 고성능 시스템을 갖춘 Graphcore가 AI 연산 분야의 떠오르는 기업이라는 사실이 공고해졌습니다.
MLPerf는 Graphcore를 비롯하여 인공 지능 업계의 회원사 및 계열사, 비영리단체와 상업회사 50개 이상이 함께 설립한 MLCommonsTM가 주관합니다.
Graphcore는 MLCommons의 목표인 "머신 러닝 혁신 가속화 및 머신 러닝이 사회에 미치는 긍정적인 영향 증대"를 적극적으로 지지합니다.
MLCommons는 분기마다 교대로 교육 및 추론 결과를 공개합니다. Graphcore가 결과를 제출한 최종 훈련 회차의 원시 데이터는 여기서 확인할 수 있습니다.
Graphcore는 MLPerf(훈련 버전 1.0)에 최초로 결과를 제출하면서 핵심적인 애플리케이션 벤치마크 카테고리인 이미지 분류 및 자연어 처리에 중점을 두었습니다.
MLPerf 이미지 분류 벤치마크는 자주 사용되는 ResNet-50 버전 1.5 모델을 사용합니다. 이 모델은 모든 제출물에서 공통적으로 지정된 정확도를 달성하도록 ImageNet 데이터 세트에서 훈련되었습니다.
NLP의 경우 BERT-Large 모델을 사용했으며, 전체 훈련 연산 워크로드의 약 10%를 대변하는 세그먼트를 Wikipedia 데이터 세트를 사용하여 훈련했습니다.
Graphcore가 ResNet-50과 BERT를 사용하여 이미지 분류와 NLP를 제출하기로 한 이유는 당사의 고객과 잠재 고객이 이러한 애플리케이션과 모델을 가장 많이 사용하기 때문입니다.
Graphcore가 MLPerf에서 보여준 탁월한 성능은 당사 시스템이 오늘날의 AI 연산 요건을 완벽하게 충족한다는 또 하나의 증거입니다.
Graphcore는 IPU-POD16 및 IPU-POD64.시스템의 MLPerf 훈련 결과를 제출했습니다.
두 시스템 모두 시판 중이므로 분류는 '프리뷰'가 아닌 '가용'으로 지정했습니다. 최초의 MLPerf 제출임을 감안하면 상당한 성과인 셈이죠!
IPU-POD16는 IPU AI 연산 능력을 구축하기 시작한 기업 고객을 위한 Graphcore의 컴팩트하고 합리적인 가격의 5U 시스템입니다. 1U IPU-M2000 4대와 듀얼 CPU 서버를 갖춘 이 시스템은 4 PetaFLOPS의 AI 연산 성능을 제공합니다.
이보다 높은 단계의 IPU-POD64 시스템은 IPU-M2000 16대를 갖추었으며, 서버 수를 유연하게 조정할 수 있습니다. Graphcore 시스템은 서버와 AI 가속기가 분리되어 있어 고객이 워크로드에 따라 원하는 CPU 대 IPU 비율을 지정할 수 있습니다. 예를 들어, 컴퓨터 비전 과제는 보통 자연어 처리보다 더 많은 서버를 필요로 합니다.
MLPerf 훈련 시 IPU-POD64는 BERT의 경우 단 한 대의 서버를 사용했으며, ResNet-50에는 네 대의 서버를 사용했습니다. 각 서버는 AMD EPYC™ CPU 두 대로 운용되었습니다.
MLPerf는 개방형과 폐쇄형의 두 가지 제출 부문을 운영합니다.
폐쇄형 부문의 경우, 제출자들은 하이퍼 파라미터 상태와 훈련 시기 지정을 비롯하여 똑같은 모델 구현과 옵티마이저 방식을 사용해야 합니다.
개방형 부문은 폐쇄형 부문과 똑같은 모델 정확도와 품질 달성을 요구하되 보다 유연한 모델 구현을 허용하여 혁신을 촉진합니다. 이에 따라 다양한 프로세서 성능과 옵티마이저 접근법에 적합한 더 빠른 모델 구현이 가능합니다.
Graphcore의 IPU와 같은 혁신적인 아키텍처의 경우 개방형 부문이 당사의 성능을 더 정확하게 나타냅니다. 그럼에도 불구하고 Graphcore는 개방형 부문과 폐쇄형 부문 모두에 결과를 제출하기로 했습니다.

Graphcore 시스템은 조건이 엄격하게 지정된 폐쇄형 부문에서도 탁월한 성능을 보였습니다.
물론 당사의 IPU 및 시스템 역량을 최대한 활용할 수 있는 최적화의 배포가 가능했던 개방형 부문에서는 더욱 돋보이는 결과가 도출되었습니다. 이 부문은 고객이 사용 가능한 성능 개선을 활용할 수 있는 실제 사용 사례와 보다 가깝습니다.
MLPerf는 여러 제조사의 기술을 평가할 때 인용되는 비교 벤치마크로 알려져 있습니다.
하지만 실제로는 직접 비교가 매우 복잡할 수 있습니다. 오늘날의 프로세서와 시스템 아키텍처는 비교적 간단한 실리콘에서부터 값비싼 메모리를 포함하는 복잡하게 스택된 칩까지 다양하기 때문입니다.
Graphcore는 고객들과 마찬가지로 달러당 성능을 살펴보는 것이 매우 유용하다고 생각합니다.
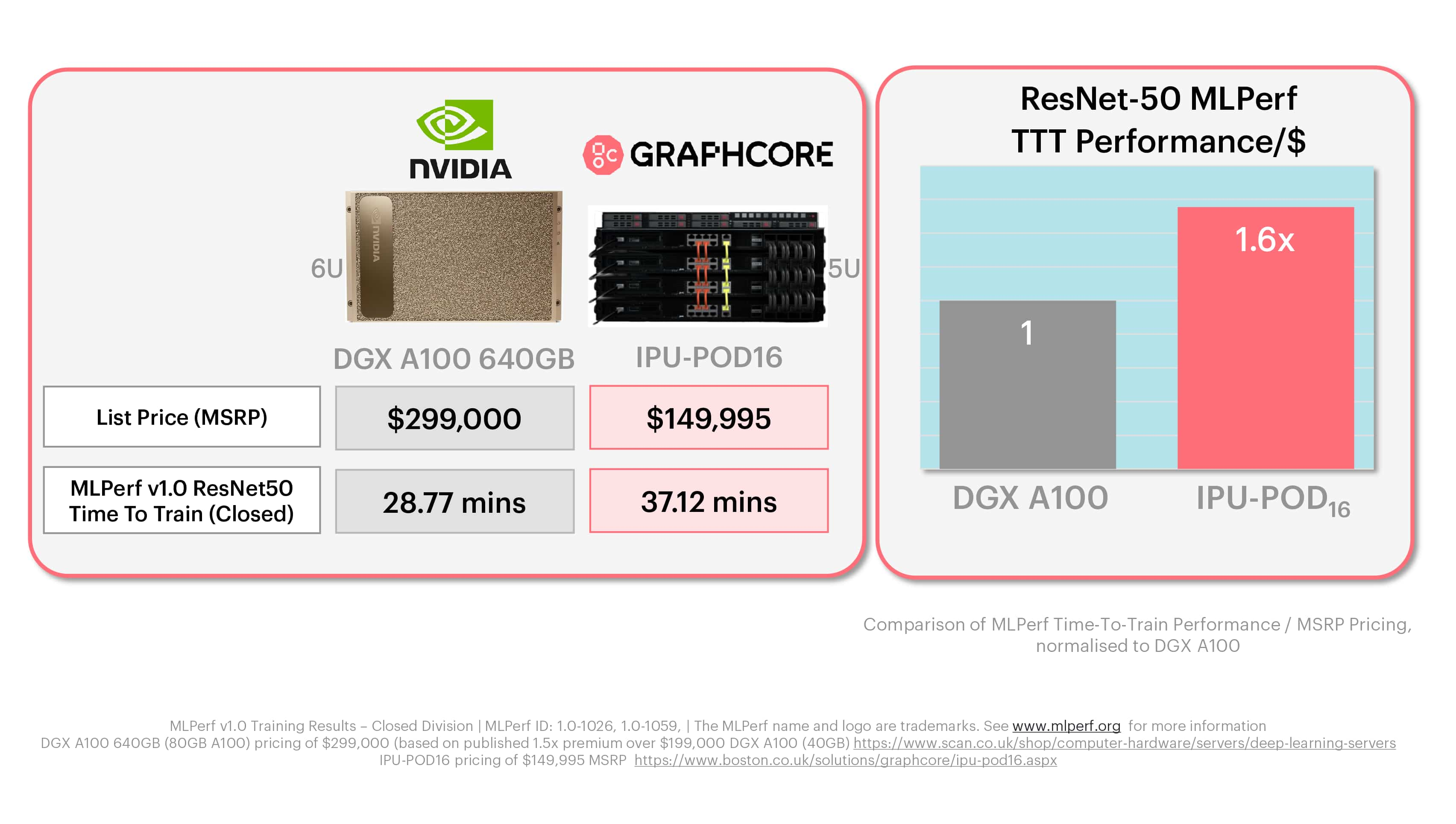
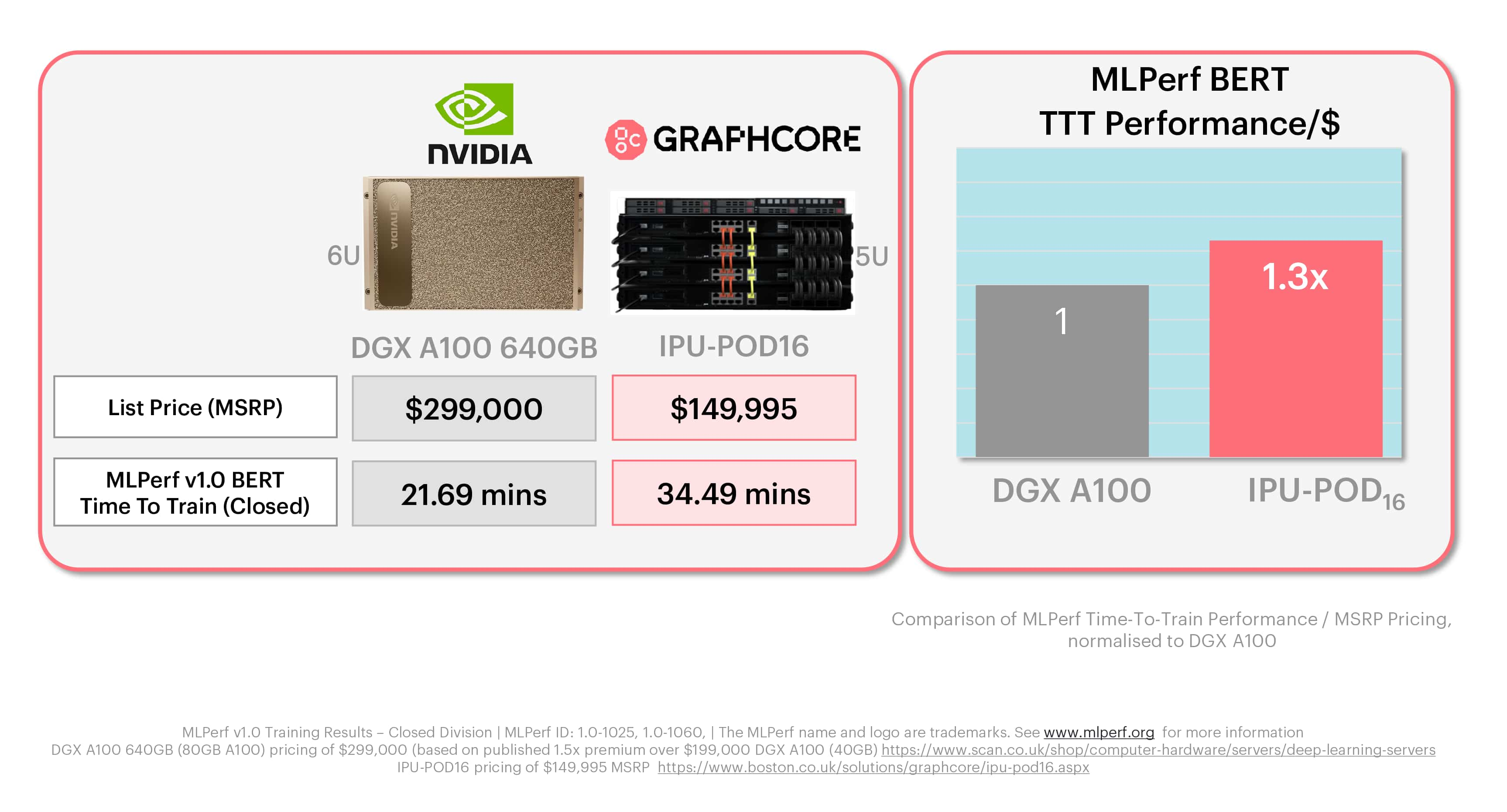
Graphcore의 IPU-POD16는 정가 $149,995의 5U 시스템입니다. 앞서 설명했듯이 이 시스템은 IPU-M2000 가속기 네 대를 탑재하며, 각각의 가속기에는 IPU 프로세서 4개와 업계 표준에 부합하는 호스트 서버가 포함되어 있습니다. MLPerf에 사용된 NVIDIA DGX-A100 640GB는 정가 $300,000 가량(시장 정보 및 리셀러 공개 가격)의 6U 박스로, DGX A100 칩 8개가 탑재되어 있습니다.
IPU-POD16는 가격이 절반에 불과하며, 가속기 기준으로 보면 IPU-M2000이 A100-80GB 한 대와 같은 가격임을 알 수 있습니다. 좀 더 자세히 말하자면, IPU 한 대의 가격은 NVIDIA DGX-A100 640GB의 1/4입니다.
MLPerf 비교 분석에서는 조건이 엄격한 폐쇄형 부문의 결과를 시스템 가격에 대입하여 정규화했습니다.
ResNet-50과 BERT 모두 Graphcore 시스템이 NVIDIA 제품에 비해 훨씬 더 우수한 달러당 성능을 제공한다는 것이 명확합니다.
ResNet-50 훈련에서는 Graphcore IPU-POD16의 달러당 성능이 NVIDIA 제품 대비 1.6배였으며, BERT에서는 1.3배에 달했습니다.
이러한 MLPerf 차트는 실제 Graphcore 고객의 경험과 일치합니다. 즉, 고객은 Graphcore 시스템의 경제성 덕분에 AI 연산 목표를 더 효과적으로 달성하고 AI에 최적화된 IPU의 아키텍처를 통해 차세대 모델과 기법을 개발할 수 있습니다.
Graphcore는 첫 MLPerf 제출에서 이렇게 탁월한 결과를 도출했다는 사실을 매우 자랑스럽게 생각합니다. Graphcore 고객 엔지니어링 그룹에 소속된 소수의 엔지니어와 회사 전체의 직원들은 이러한 성과를 위해 치열하게 노력했습니다.
더 나아가 Graphcore는 이번 제출물에 적용한 개선 사항과 최적화를 당사 소프트웨어 스택에도 적용함으로써 이번 MLPerf 참여의 의의를 더욱 빛냈습니다. 전 세계의 Graphcore 사용자들이 BERT와 ResNet-50뿐 아니라 수많은 다른 모델에서도 MLPerf의 성과를 체험하고 있습니다.
Graphcore는 앞으로도 MLPerf의 훈련 및 추론 부문 모두에 지속적으로 참여하여 더 나은 성과, 더 큰 규모와 새로운 모델 추가라는 세 가지 목표를 모두 달성할 것입니다.
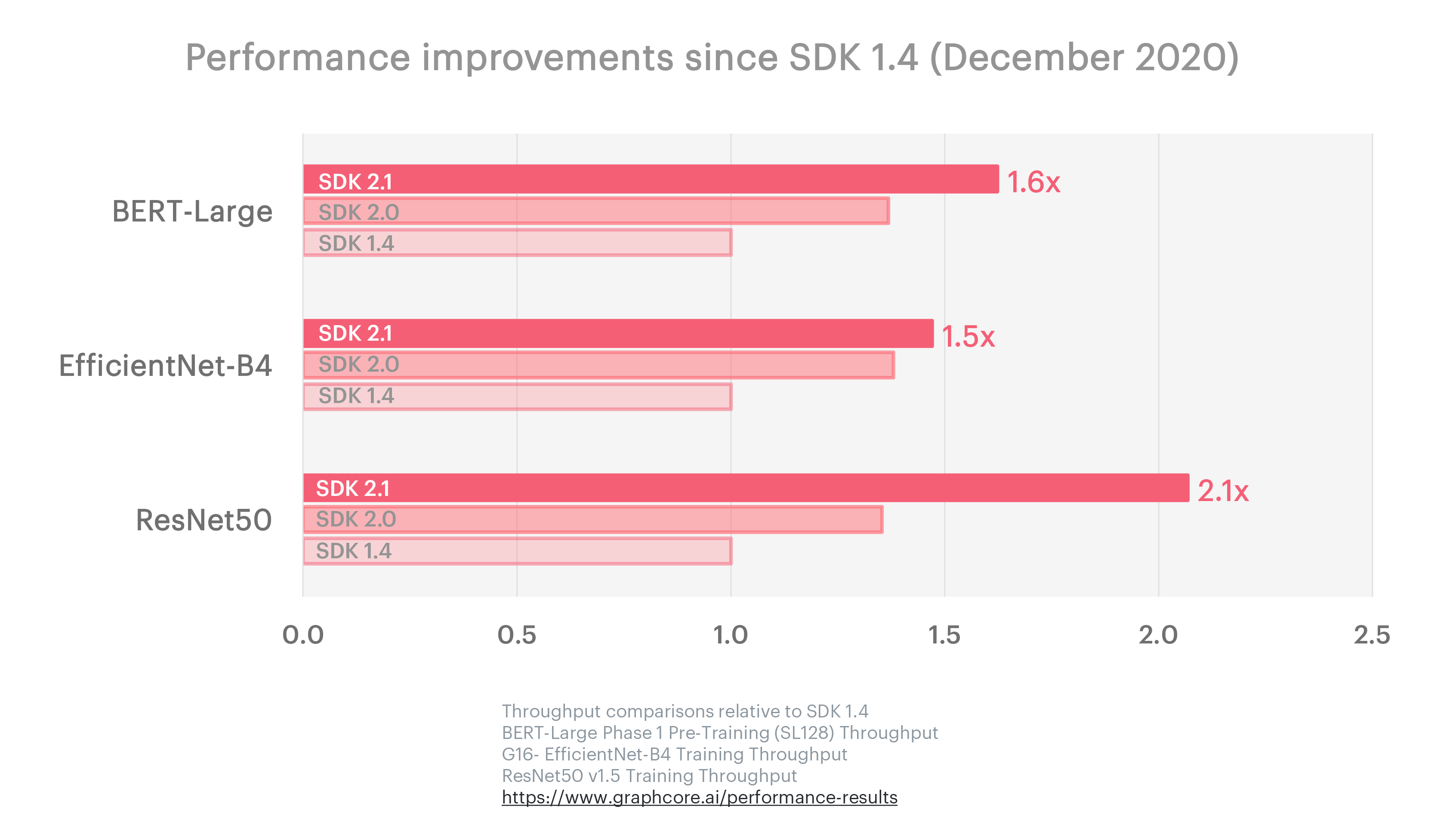
지속적인 소프트웨어 개선에 중점을 둔 Graphcore의 방향성은 Poplar SDK의 최근 릴리스에 적용된 벤치마크 진행 상황에도 뚜렷하게 반영되었습니다. Graphcore는 2020년 12월부터 2021년 6월까지 6개월 동안 세 번의 업데이트를 거치며 ResNet-50의 성능을 2.1배 끌어올리고, BERT-Large의 성능은 1.6배 개선했으며, ResNet보다 더 높은 정확성을 목표로 하는 컴퓨터 비전 모델 EfficientNet의 성능을 1.5배 향상했습니다.
Graphcore의 리서치 팀 또한 지속적인 소프트웨어 개선이라는 목표에 부응하여 현행 모델과 차세대 모델로 가능한 사항의 한계를 더욱 넓혀가고 있습니다. 최근 발행된 'EfficientNet를 보다 효율적으로 만드는 방법'과 '프록시 정규화 활성화를 통해 CNN(합성곱 신경망)에서 배치 종속성 제거'는 MLPerf를 준비하는 과정에서 완수한 작업과 직접적으로 관련된 내용으로, Graphcore 고객뿐 아니라 AI 커뮤니티 전체에 도움이 됩니다.
Graphcore는 오늘날 가장 널리 사용되는 AI 모델을 통해 당사의 성능을 입증하기 위해 MLPerf에서 ResNet-50과 BERT의 결과를 가장 먼저 제출했습니다.
하지만 Graphcore의 IPU와 이를 기반으로 한 시스템은 차세대 AI 애플리케이션에서도 탁월한 성능을 제공하고 사용자가 기존 프로세서 아키텍처의 한계에서 벗어나 새로운 모델과 기법을 개발할 수 있도록 설계되었습니다.
이러한 모델 중 하나는 EfficientNet-B4입니다. 이 모델은 제법 널리 사용되는 고급 컴퓨터 비전 모델로, IPU와 GPU 간 점점 더 벌어지는 달러당 성능 격차를 보여줍니다.
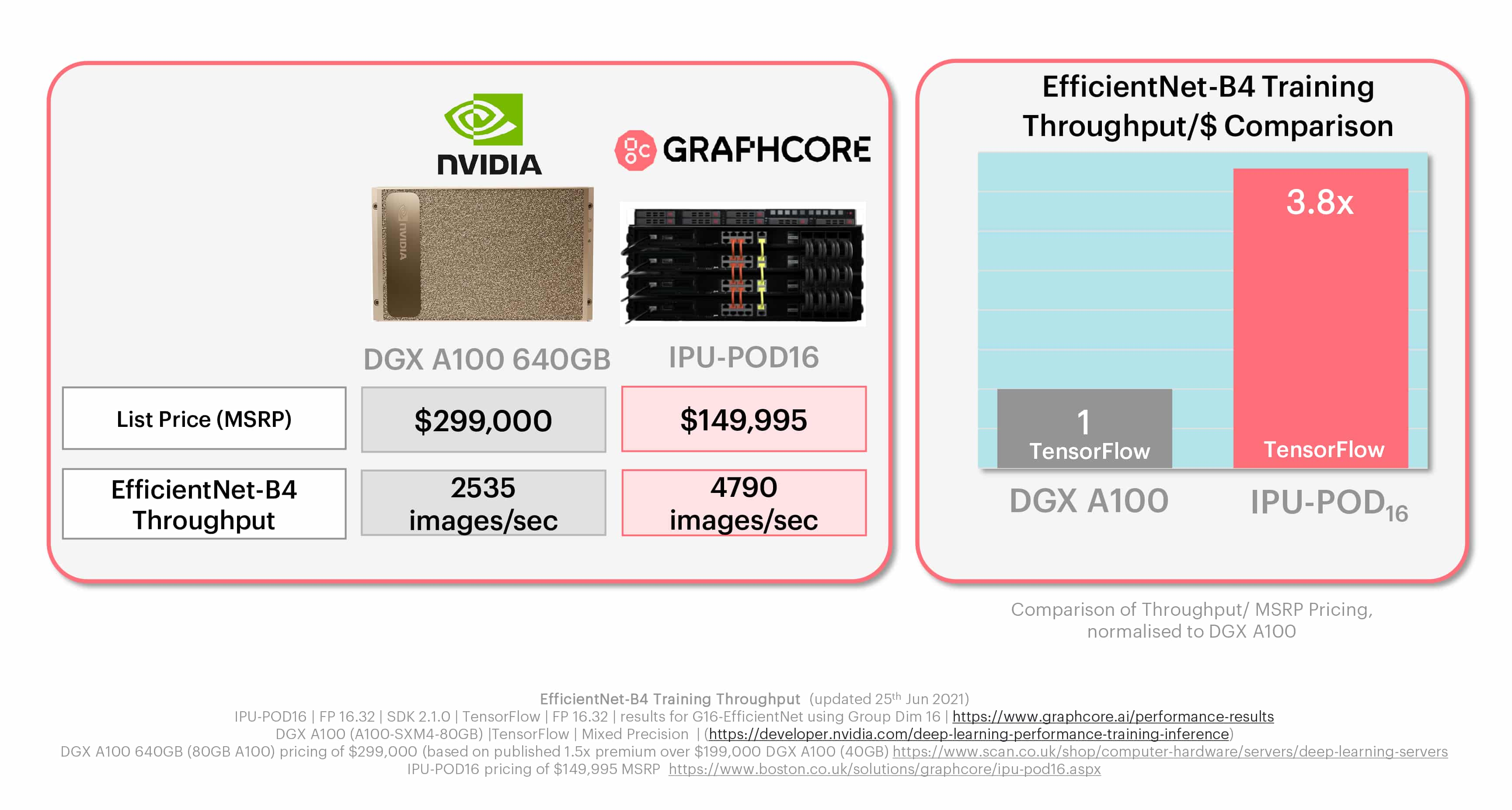
Graphcore는 지속적으로 이러한 혁신적인 모델의 추세를 따라가는 동시에 오늘날의 가장 보편적인 사용 사례를 반영하는 MLPerf가 고객과 AI 업계에 유용한 인사이트를 제공하리라 생각합니다.
당사는 저희 기술을 사용하는 분들과 그렇지 않은 분들 모두에게 도움을 드릴 수 있도록 앞으로도 계속해서 MLCommons에 적극적으로 참여할 것입니다.
이제 Graphcore는 첫 제출의 우수한 결과를 기념하면서 다음 제출을 준비할 예정입니다.
공유:

