
Sep 17, 2021 \ Poplar, Software
Sep 17, 2021 \ Poplar, Software
공유:
허깅페이스는 AI 하드웨어 서밋 2021에서 연설하면서 장치 최적화 모델과 소프트웨어 통합을 포함하는 새로운 하드웨어 파트너 프로그램을 출시한다고 발표했습니다. 그래프코어는 이 프로그램의 초기 참여 멤버입니다. 그래프코어와 허깅페이스의 협업은 개발자가 SOTA 트랜스포머 모델을 더 많이 사용하도록 가속화할 것입니다.
그래프코어와 허깅페이스는 혁신가들이 머신 인텔리전스의 힘을 활용할 수 있도록 돕는다는 공통의 목표를 가지고 있습니다.
허깅페이스의 하드웨어 파트너 프로그램을 통해 그래프코어 시스템을 사용하는 개발자는 최소한의 코딩으로 그래프코어의 IPU에 최적화된 SOTA 트랜스포머 모델을 실제 개발에 사용할 수 있게 됩니다.
IPU는 그래프코어의 IPU-POD 데이터 센터 컴퓨팅 시스템을 구동하는 프로세서입니다. 이 새로운 유형의 프로세서는 AI 및 머신러닝의 매우 특정한 계산 요구 사항을 지원하도록 설계되었습니다. 또한 세분화된 병렬 처리, 저정밀도 연산, 그리고 희소성 처리 기능에 특화되어 있습니다.
그래프코어의 IPU는 GPU와 달리 SIMD/SIMT 아키텍처를 채택하는 대신, 실리콘 다이의 프로세서 코어에 인접한 초고대역폭 메모리와 대규모 병렬 MIMD 아키텍처를 사용합니다.
이러한 설계는 BERT, EfficientNet 같이 현재 가장 인기 있는 모델을 실행하거나, 차세대 AI 용용 분야를 탐색할 때 뛰어난 성능과 새로운 차원의 효율성을 제공합니다.
소프트웨어는 IPU의 기능을 최대한으로 활용하는 데 중요한 역할을 합니다. 그래프코어의 Poplar SDK는 회사 창립 때부터 프로세서와 공동으로 설계되었습니다. 또한 PyTorch, TensorFlow를 비롯한 표준 머신러닝 프레임워크와 Docker, Kubernetes를 비롯한 오케스트레이션 및 배포 도구와 완벽하게 통합됩니다.
Poplar는 이처럼 광범위하게 사용되는 서드파티 시스템과 완벽하게 호환되므로 개발자들은 다른 컴퓨팅 플랫폼에서 모델을 쉽게 포팅하고 IPU의 고급 AI 기능을 활용할 수 있습니다.
트랜스포머는 AI 분야를 완전히 혁신했습니다. 그래프코어 고객들은 자연어 처리(NLP)를 비롯한 다양한 응용 분야에서 BERT 같은 모델을 널리 사용합니다. 이러한 다재다능한 모델은 특징 추출, 텍스트 생성, 감성 분석, 번역 등 다양한 영역에서 활용됩니다.
허깅페이스는 프랑스어 언어 CamemBERT부터 NLP 노하우를 컴퓨터 비전에 적용하는 ViT에 이르기까지 수백 개의 트랜스포머를 보유하고 있습니다. 허깅의 트랜스포머 라이브러리는 매달 200만 회 이상 다운로드되며, 그 수요는 점점 더 증가하고 있습니다.
50,000명 이상의 개발자가 사용자로 있는 허깅페이스는 오픈소스 프로젝트에 매우 빠르게 채택되고 있습니다.
이제 허깅페이스는 하드웨어 파트너 프로그램을 통해 최고의 트랜스포머 도구 세트를 현존 최고의 AI 하드웨어와 결합할 계획입니다.
개발자들은 새로운 오픈소스 라이브러리 및 툴킷 Optimum를 사용하여 허깅페이스의 인증을 거친 하드웨어 최적화 모델을 이용할 수 있습니다.
이러한 사항들이 그래프코어와 허깅페이스의 협업을 통해 개발 중인 가운데, 첫 번째 IPU 최적화 모델은 올해 말 Optimum에 등장할 전망입니다. 이는 궁극적으로는 시각, 음성, 번역, 텍스트 생성 등 다양한 응용 분야에서 활용될 수 있습니다.
허깅페이스의 CEO인 Clément Delangue 씨는 이렇게 말합니다. "모든 개발자들은 그래프코어 IPU와 같은 최고의 성능을 자랑하는 최신 하드웨어를 이용하고 싶어하지만, 새로운 코드나 프로세스를 배워야 하는지에 대해 늘 의문스러워 합니다. Optimum과 허깅페이스 하드웨어 프로그램에는 그러한 문제가 전혀 없습니다. 본질적으로 플러그 앤 플레이 방식이니까요."
허깅페이스와의 협업을 발표하기에 앞서 그래프코어는 PyTorch를 사용하는 허깅페이스 BERT의 특별한 그래프코어 최적화 구현을 통해 SOTA 트랜스포머 모델을 가속화하는 IPU 기능을 시연했습니다.
이에 대한 자세한 내용은 IPU의 BERT-Large 학습 블로그에서 확인할 수 있습니다.
유사한 GPU 기반 시스템과 비교해볼 때, 그래프코어 시스템에서 실행되는 BERT의 놀라운 벤치마크 결과는 현재 IPU를 사용하지 않고 인기 NLP 모델을 실행하는 고객들에게 깊은 감명을 줄 것입니다.
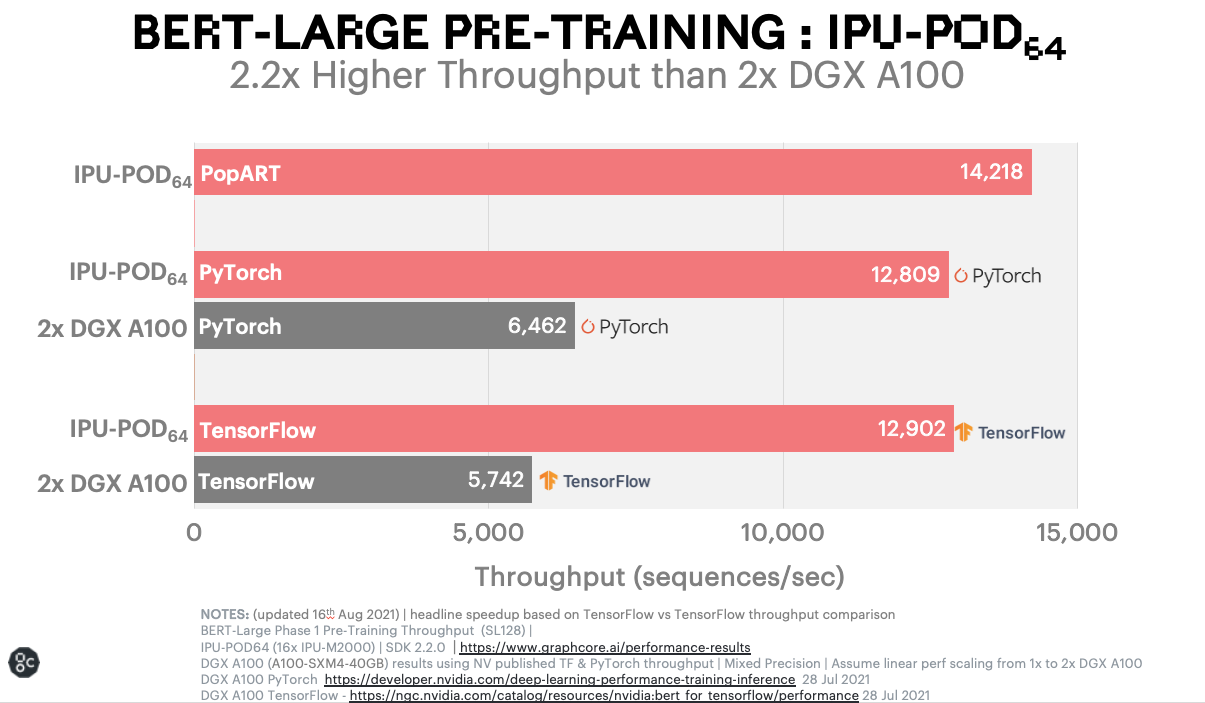
이러한 유형의 가속화는 머신러닝 연구원 및 엔지니어가 교육에 소비하는 시간을 대폭 줄이고 새로운 모델 개발에서 더 많은 반복을 수행하도록 지원하는 등 획기적인 혜택을 제공합니다.
이제 그래프코어 사용자들은 뛰어난 단순성과 최상급 모델을 제공하는 허깅페이스 플랫폼을 통해 이러한 성능 이점을 누릴 수 있습니다.
허깅페이스와 그래프코어는 더 많은 사람들이 트랜스포머의 기능을 활용하여 AI 혁명을 가속화할 수 있도록 지원합니다.
자세한 내용은 허깅페이스 하드웨어 파트너 포털에서 확인하세요.
공유:

