
Jun 08, 2021 \ Finance, Research, University
Jun 08, 2021 \ Finance, Research, University
공유:
맨 그룹 (Man Group)이 옥스퍼드 대학과의 혁신적인 산학협력을 위해 설립한 Oxford-Man Institute of Quantitative Finance(이하 OMI)의 연구원들은 그래프코어의 IPU를 활용하여 고급 가격 예측 모델의 훈련 속도를 대폭 개선했습니다. 여기서 OMI가 활용한 기술은 IPU가 아닌 다른 프로세서에서 실행할 경우 보통 연산 병목 현상이 발생합니다.
OMI 팀은 AI에 최적화된 설계의 IPU를 활용해 다중 전망 예측 모델의 훈련 시간을 단축함으로써 시장 가격 동향 예측의 정확도를 높여 상업적 경쟁에서 우위를 확보할 수 있었습니다. 이러한 모델은 속성 거래용 알파 개발과 시장 개척 전략에 적용할 수 있습니다.
금융시장 내 입찰가/호가 수준의 기록과도 같은 지정가 주문(LOB) 시스템은 수백만 건의 매수/매도 주문에 나타난 트레이더의 여론을 실시간으로 보여줍니다. 지정가 주문을 분석하면 가격 변화를 예측할 수 있습니다. 이러한 예측은 시장 참여자에게 매우 유용하며, 소위 '핫한' 주식을 선택하기보다는 거래를 실행할 최적의 순간을 파악하는 데 도움이 됩니다.
인공지능은 LOB 데이터를 수동 분석이나 기존의 연산보다 훨씬 더 복잡한 차원에서 분석할 수 있으며, 따라서 더욱 정확한 결과를 제공할 수 있습니다.
일반적으로 이 분야에서 AI를 활용하려는 노력은 특정 입찰가/호가와 이의 결과에 해당하는, 미리 지정한 미래 시점(또는 전망)의 시장가 간 관계를 파악하는 단일 전망 예측에 집중되어 왔습니다.
반면 다중 전망 예측은 이름에서도 알 수 있듯이 일련의 간격에 걸친 가격 변화를 분석하며, 각 전망의 결과가 다음 전망의 기반이 됩니다. 이러한 전망의 누적을 통해 훨씬 더 장기적인 예측을 수행할 수 있습니다.
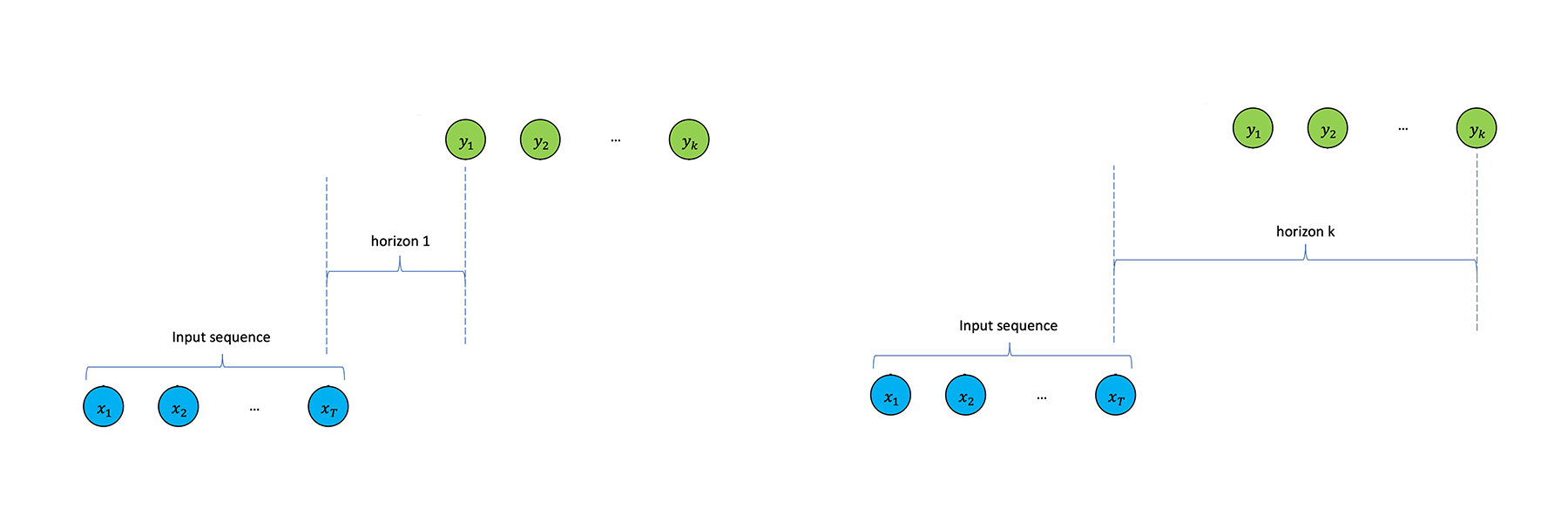
그러나 다중 전망 예측 모델은 주로 CPU 및 GPU의 느린 학습 속도로 인해 유용성이 낮다고 평가받아 왔습니다.
OMI의 연구자인 Zihao Zhang 박사와 Stefan Zohren 박사는 IPU의 아키텍처가 다중 전망 예측에서 사용되는 반복 신경망(neural) 레이어에 훨씬 더 적합하며 연산 병목 현상이 발생하지 않는다는 점에 착안했습니다.
그 결과, 높은 정확도로 이전의 기법보다 훨씬 더 빠르게 다중 전망 모델을 훈련시키는 솔루션을 고안해냈습니다.
Zhang 박사는 "흥미로운 최신 네트워크를 여럿 벤치마크했는데, IPU가 일반 GPU보다 최소한 몇 배는 더 빠르다는 사실을 확인할 수 있었다”며, “구체적으로 말하면 10배는 더 빠를 것"이라며 IPU의 효율성을 평가했습니다.
맨 그룹의 다변화 계량 투자를 이끌고 있는 맨 AHL은 이 OMI 연구의 상업적 적용 가능성을 평가 중입니다.
맨 AHL의 수석 과학자인 Anthony Ledford 박사는 "IPU가 이러한 유형의 계산을 훨씬 더 빠르게 할 수 있다는 사실이 확인되면 분명 수요가 더 높아질 것”이라고 말했습니다.
보통 단일 전망 예측은 표준 감독 학습 문제로 취급됩니다. 이 예측의 목적은 특정 시점에 지정가 주문의 매수가/매도가와 이로 인한 시장가 사이의 관계를 파악하는 것입니다. 그러나 시장가에 영향을 미치는 요인이 워낙 다양하고 유용한 신호의 비율은 상대적으로 낮기 때문에 단일 전망에서 장기 예측 경로를 추론하기는 어렵습니다.
다중 전망 예측을 실현하기 위한 한 가지 기법에서는 자연언어처리(NLP)에서 자주 사용되는 방법을 차용하여, 인코더와 디코더가 포함된 복잡한 반복 신경망 레이어에 기반한 시퀀스-투-시퀀스 모델 (Seq2Seq Model) 및 어텐션 모델(Attention Model)을 활용합니다. 시퀀스-투-시퀀스 인코더는 과거의 시계열 정보를 요약하며, 디코더는 숨겨진 상태를 미래의 알려진 입력과 조합하여 예측을 생성합니다. 어텐션 모델은 긴 시퀀스를 처리하지 못하는 시퀀스-투-시퀀스 모델의 한계를 극복하는 데 일조합니다.
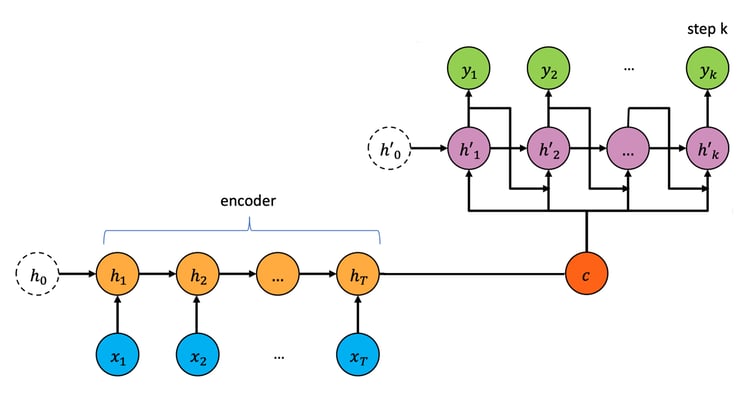
그러나 이러한 모델의 반복 구조는 GPU와 같은 프로세서 아키텍처의 병렬 처리에 맞지 않습니다. 현대 전자 거래의 높은 LOB 데이터 생산 비율을 감안했을 때 이러한 한계는 특히 큰 문제로 작용합니다.
이러한 연산 문제를 해결하기 위해 완전히 연결된 계층으로 구성된 트랜스포머를 비롯하여 몇 가지 솔루션이 제안된 바 있습니다.
그러나 OMI 팀은 시퀀스-투-시퀀스/어텐션 조합의 반복 구조가 과거 정보를 요약하여 차후 타임스탬프로 전파할 수 있어 다중 전망 예측의 시계열 특성에 적합하다고 느꼈습니다.
이 방식을 실용화하기 위해 성능이 더 좋은 연산 플랫폼이 필요했던 OMI 팀은 그래프코어의 기술을 차용, 획기적으로 다른 아키텍처인 IPU를 활용하여 접근 방식을 테스트하기 시작했습니다.
LOB 데이터는 IPU에서 여러 모델을 훈련하는데 사용되었습니다. 활용한 LOB 데이터에는 같은 OMI 팀이 이전에 개발한 DeepLOB도 포함되었습니다(Zhang et al, 2019). 다중 전망 예측과 관련하여 연구자들은 두 개의 DeepLOB 변형을 테스트했는데, DeepLOB-Seq2Seq와 DeepLOB-Attention으로 명명된 두 변형은 각각 시퀀스-투-시퀀스 모델과 어텐션 모델을 디코더로 활용합니다.
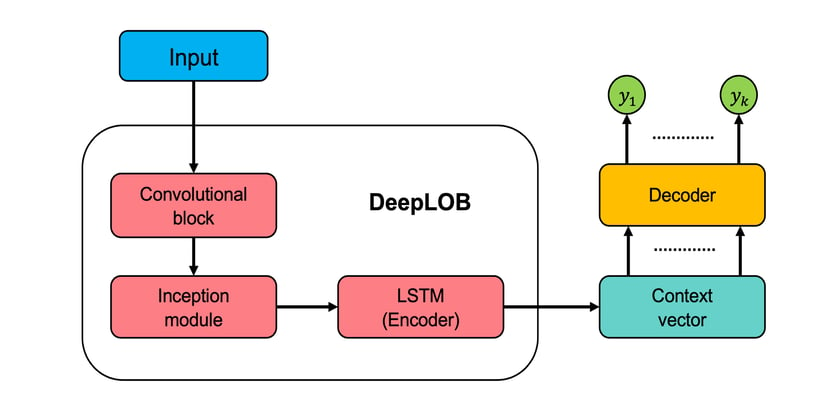
DeepLOB-Seq2Seq와 DeepLOB-Attention을 포함한 다양한 모델에서 Graphcore IPU는 비교 대상인 GPU에 비해 학습 시간(time-to-train)에서 압도적인 성능을 보였습니다.
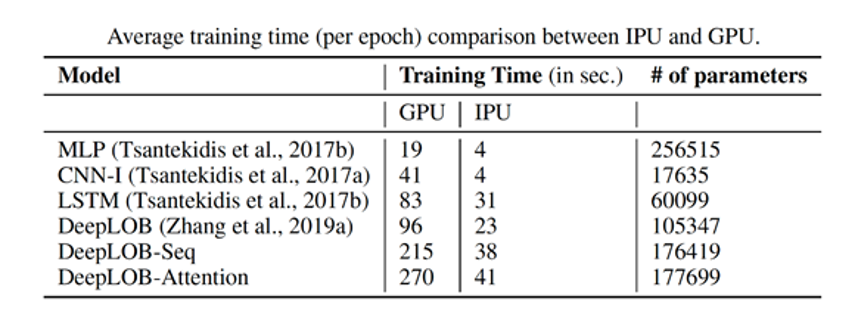
또한 새로운 모델들은 단기 전망(예: K=10)뿐 아니라 장기 전망(예: K=50, K=100)에서도 예측 정확도가 더 높았습니다. 여기서 K는 '틱 타임(tick time)', 즉 거래에서 메시지를 수신하는 이벤트 시간을 의미합니다. 이 시간은 유동성이 높은 주식일수록 빠르고, 유동성이 낮은 주식일수록 느립니다. 특히 다중 전망 모델 DeepLOB-Seq2Seq와 DeepLOB-Attention은 보다 장기적인 전망의 예측을 수행하는 경우 가장 높은 수준의 정확도와 정밀도를 보였습니다.
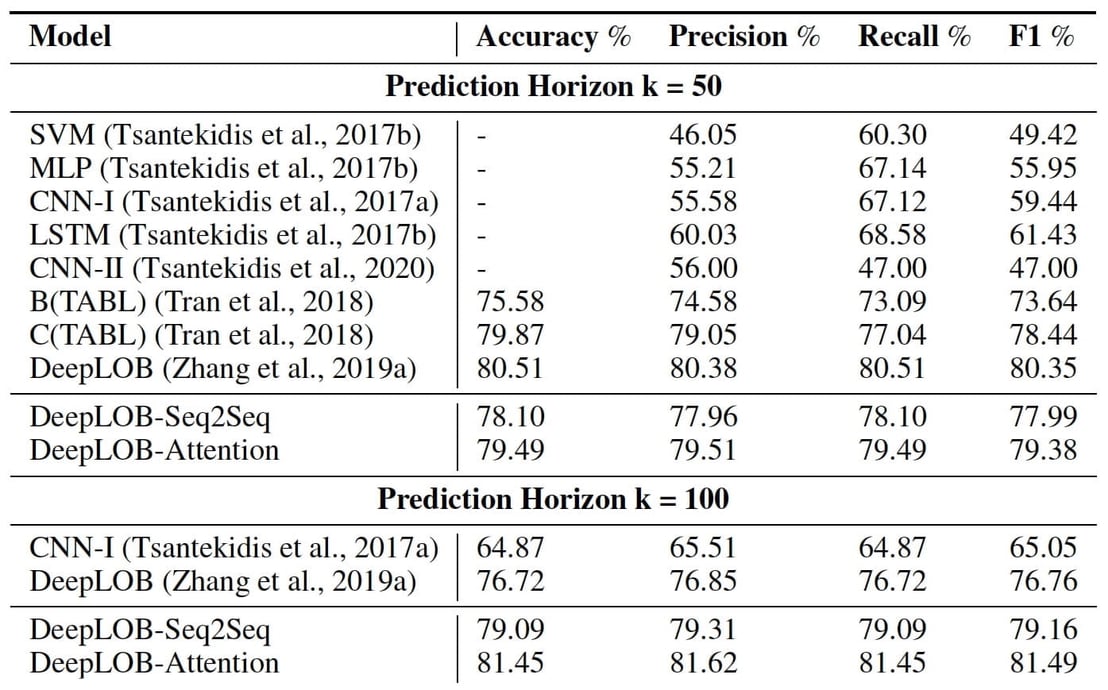
OMI의 논문에서 모델 유형과 다중 전망 성과가 모두 수록된 표를 확인할 수 있습니다.
Zhang 박사와 Zohren 박사는 그래프코어 IPU를 사용하여 도출한 원칙을 온라인 학습이나 시장 확보를 위한 강화 학습 등 다양한 용도에 활용할 수 있다고 말합니다.
또한 이전의 연구 논문에서 고려한 대로 강화 학습 프레임워크에 인코더-디코더 구조(encoder-decoder structure)를 적용하는 방안도 연구 중입니다.
Zohren 박사는 "강화 학습 알고리즘은 이러한 다중 전망 예측을 최적의 실행 또는 시장 확보 환경에서 적용하기 위한 탁월한 프레임워크를 제공한다”며 “이와 같은 알고리즘의 연산 복잡성을 고려할 때, IPU 활용을 통한 속도 증진은 이러한 환경에서 더 클 수 있다"고 역설했습니다.
Zhang 박사와 Zohren 박사의 최신 연구 논문은 ArXiv에서, 코드는 Github에서 확인할 수 있습니다.
공유:

