
Jun 29, 2022 \ Machine Learning, Baidu, Benchmarks
Jun 29, 2022 \ Machine Learning, Baidu, Benchmarks
공유:
그래프코어 IPU 시스템의 획기적인 성능적 이점이 최신 MLPerf 벤치마크 테스트를 통해 다시 한번 입증됐습니다.
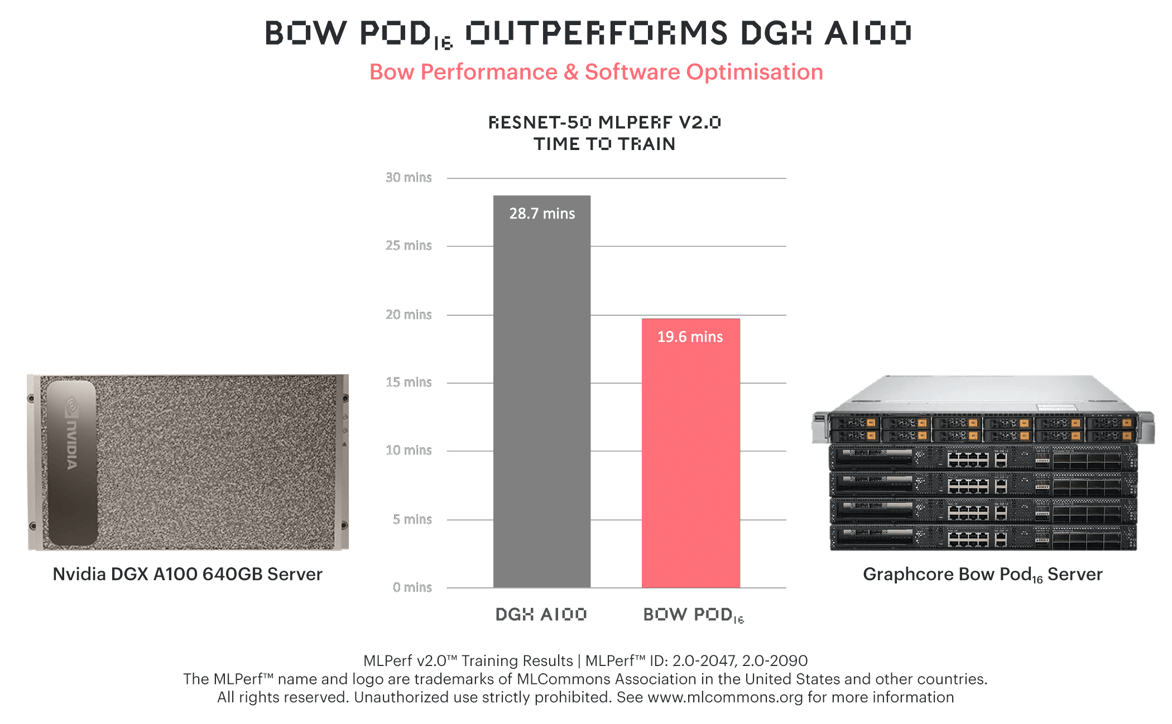
그래프코어의 Bow Pod16은 상대적으로 비용이 더 높은 엔비디아(NVIDIA)의 플래그십 모델인 DGX-A100 640GB보다 ResNet-50에서 훈련 시간이 31% 더 빨랐습니다.
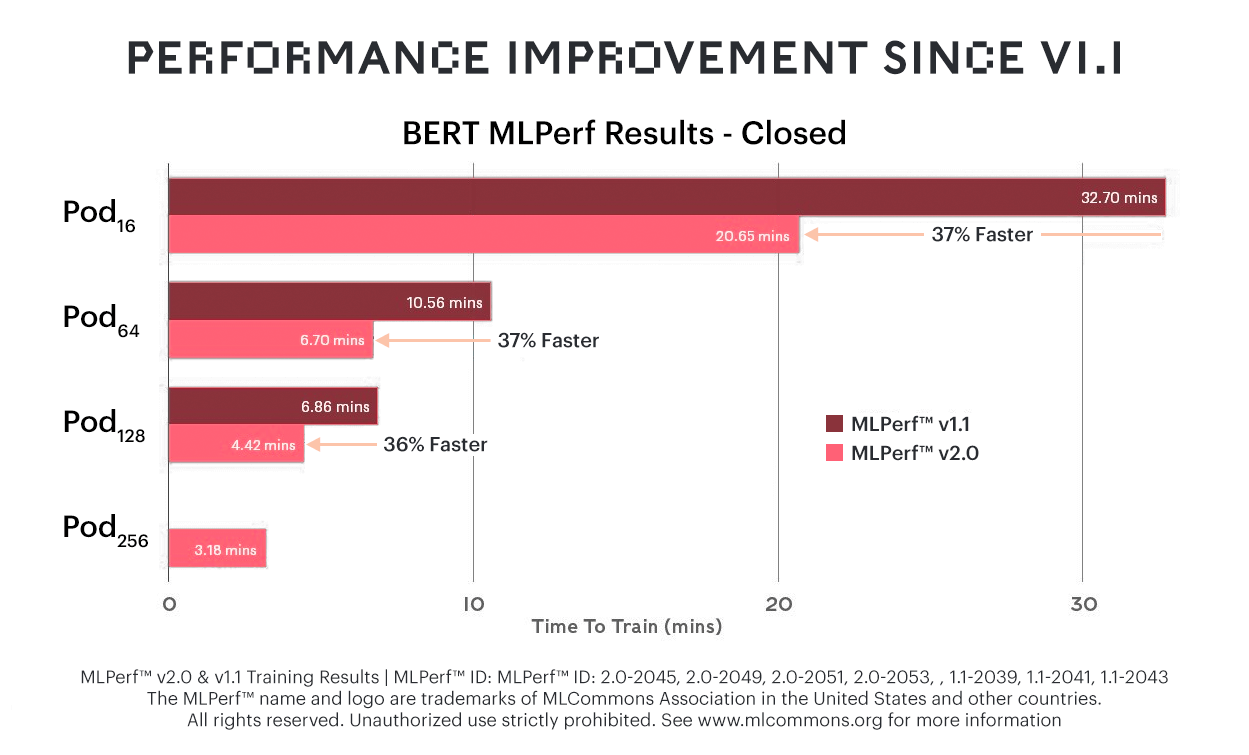
BERT에 대해서는 이전 MLPerf 벤치마크에서 보다 37% 향상된 성능을 보였는데요. 그 결과, 그래프코어 시스템은 널리 사용되는 여러 언어 모델에 걸쳐 가격 및 성능 모든 측면에서 선두자리를 지켰습니다.
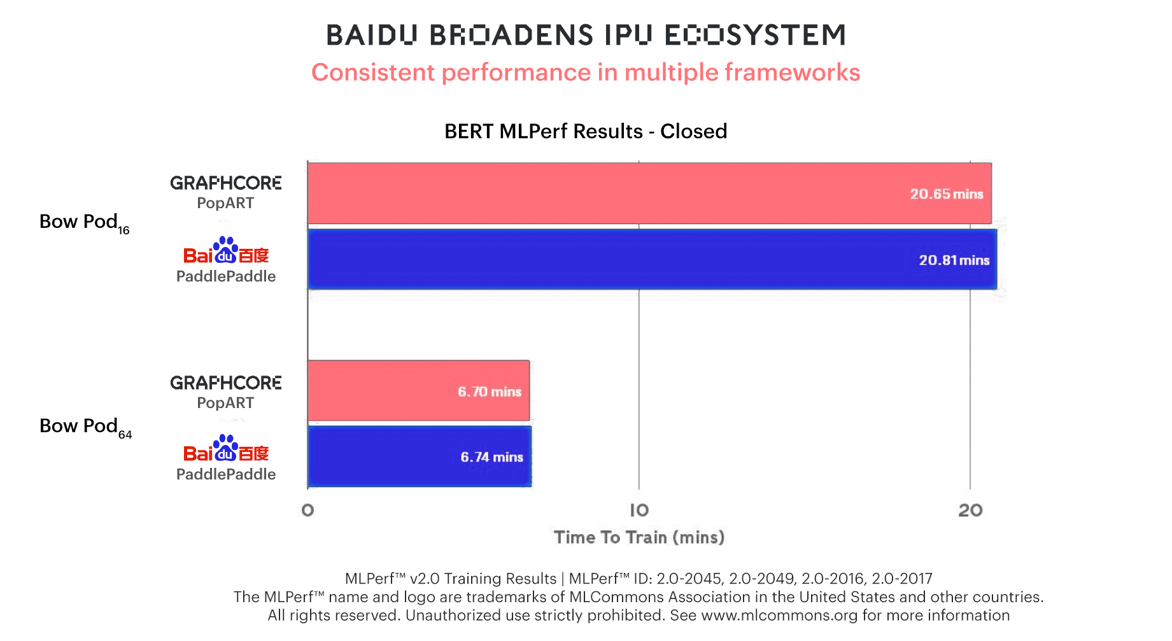
최초로 그래프코어 시스템 관련 써드파티 결과를 제출한 바이두(Baidu)는 패들패들(PaddlePaddle) 소프트웨어 프레임워크를 사용하여 BERT 훈련에서 동일한 성능을 달성했는데요. 이를 통해, IPU의 높은 사용편의성으로 생태계가 빠르게 확장되고 있음을 증명했습니다.
2021년 그래프코어는 MLPerf에 처음으로 훈련 결과를 제출하면서 오랜기간 확립된 AI 컴퓨팅 성능 측정에서 IPU의 역량을 입증하는데 집중했습니다.
그래프코어의 고객과 업계 전문가들은 ResNet과 BERT가 구축된 벡터 프로세서와 함께 IPU의 차별화된 아키텍처가 우수한 성능을 구현할 것을 기대했고, 그래프코어는 그 이상의 성과를 달성했습니다.
이러한 유용한 수치들 외에도, 그래프코어는 많은 고객들이 활용하고 있는 ResNet 및 BERT의 뒤를 잇는 모델에 집중함으로써 더 높은 수준의 정확성과 효율성을 제공하고자 합니다.
그래프신경망(GNN)과 같은 최신 모델은 IPU의 MIMD 아키텍처, 세분화된 병렬 처리는 물론, 그 외의 AI에 특화된 기능을 최대한 활용합니다. 이같은 유형의 워크로드에 대한 IPU의 성능은 오늘날 AI 컴퓨팅의 대부분을 구성하는 벡터 프로세서 아키텍처와 비교해 상당히 월등합니다.
새로운 Bow IPU와 개선된 소프트웨어가 결합된 결과, ResNet-50에 대한 훈련 시간이 이전 테스트인 MLPerf 1.1에서 보다 31%까지 단축되었습니다.
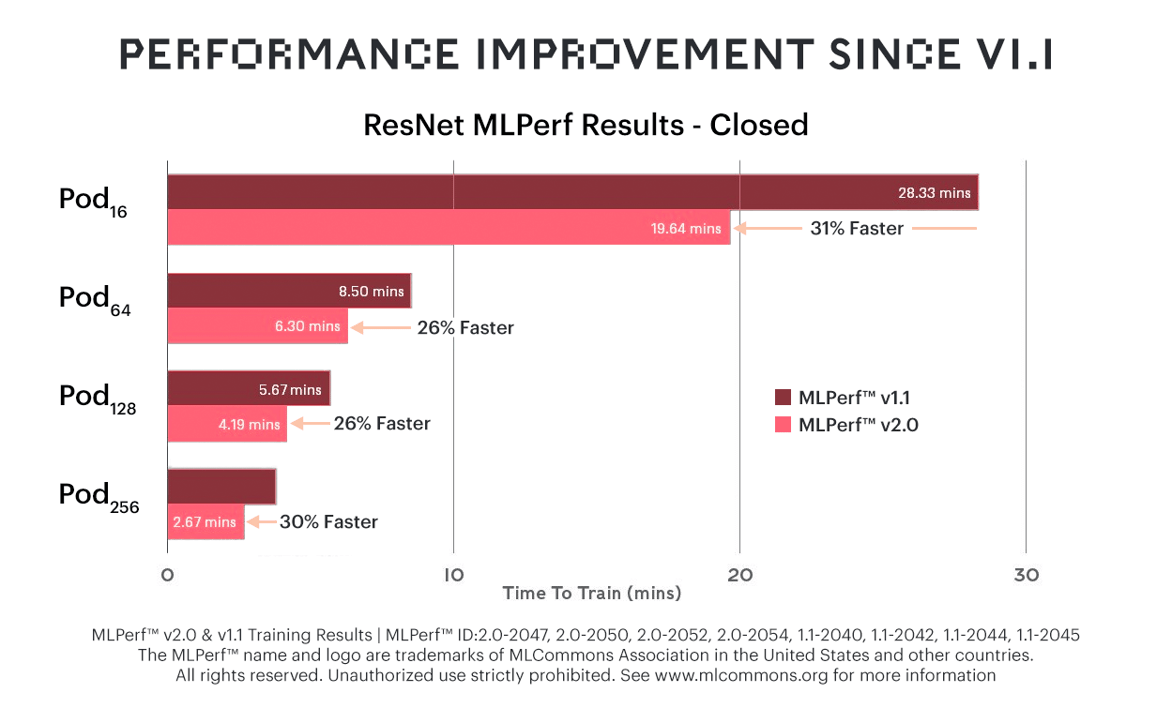 성능은 전반적으로 크게 향상됐지만, Bow Pod 시스템의 가격은 이전과 동일해 상당한 비용효율성을 제공하는데요.
성능은 전반적으로 크게 향상됐지만, Bow Pod 시스템의 가격은 이전과 동일해 상당한 비용효율성을 제공하는데요.
실제로, 많은 고객들이 비용 대비 매우 우수한 AI 컴퓨팅 성능을 제공한다는 점을 그래프코어의 IPU 시스템을 선택하는 이유로 꼽고 있습니다.
현재 DGX-A100 640GB와 같이 가격이 상당히 높은 시스템에 비해 성능상의 이점이 더욱 두드러집니다.
BERT 훈련 시간이 최대 37% 향상됐다는 것은 곧 그래프코어 시스템의 가격 대비 성능 이점이 한층 개선된 것을 의미합니다.
 바이두가 BERT 훈련에 Bow Pod16 및 Bow Pod64를 사용하여 제출한 패들패들 결과는 그래프코어가 PopART를 사용하여 제출한 결과와 유사한 양상을 보입니다.
바이두가 BERT 훈련에 Bow Pod16 및 Bow Pod64를 사용하여 제출한 패들패들 결과는 그래프코어가 PopART를 사용하여 제출한 결과와 유사한 양상을 보입니다.
이는 Bow Pod의 강력한 성능을 제3자가 검증한 것일 뿐만 아니라, IPU 생태계의 성장을 이끄는 주요 요인인 그래프코어 시스템의 유연성을 잘 보여 주는데요. 바이두는 널리 사용되는 패들패들 소프트웨어 프레임워크를 그래프코어의 포플러(Poplar)와 통합하여 탁월한 결과를 얻을 수 있었습니다.
그래프코어는 오픈(Open) 부문에서 RNN-T에 대한 결과도 제출했는데요.
RNN-T는 매우 정확한 음성 인식을 수행하는 정교한 방법으로, 훈련된 모델을 최소한의 레이턴시로 헤드셋에 로컬로 배포할 수 있기 때문에 모바일 기기에 주로 사용됩니다.
그래프코어는 이번에 고객 서비스, 컴플라이언스, 프로세스 자동화 등의 분야에서 음성 솔루션을 제공하는 자사 고객인 그리드스페이스(Gridspace)와 협력하여 RNN-T 훈련을 진행했습니다.
RNN-T 모델은 700GB 또는 1만시간의 음성으로 훈련됐는데요, Bow Pod64에서 실행되도록 확장되어 훈련 시간을 몇 주에서 단 며칠로 단축했습니다.
이번 MLPerf 2.0에 RNN-T 결과를 제출한 것은 IPU를 활용한 모델을 구현하고 최적화하기 위한 그래프코어의 고객 중심적 접근을 반영한 것이라 볼 수 있습니다.
ResNet, BERT, RNN-T 외에도 그래프코어의 리포지터리인 모델 가든(Model Garden)에서 이용할 수 있는 대부분의 IPU 지원 모델은 고객의 요구를 기반으로 탄생했는데요.
 IPU의 AI용 MIMD 아키텍처를 통해 점점 더 정교해지는 모델을 지원하고 있으며, 여기에는 수천 개의 독립적인 프로그램 스레드를 실행할 수 있는 기능도 포함됩니다.
IPU의 AI용 MIMD 아키텍처를 통해 점점 더 정교해지는 모델을 지원하고 있으며, 여기에는 수천 개의 독립적인 프로그램 스레드를 실행할 수 있는 기능도 포함됩니다.
일례로, 최근 트위터(Twitter)의 그래프 ML 연구 책임자인 마이클 브론스타인(Michael Bronstein)이 작성한 포스팅은IPU가 TGN(Temporal Graph Network)에 대해 10배의 성능 향상을 달성했다는 사실을 잘 보여줍니다.
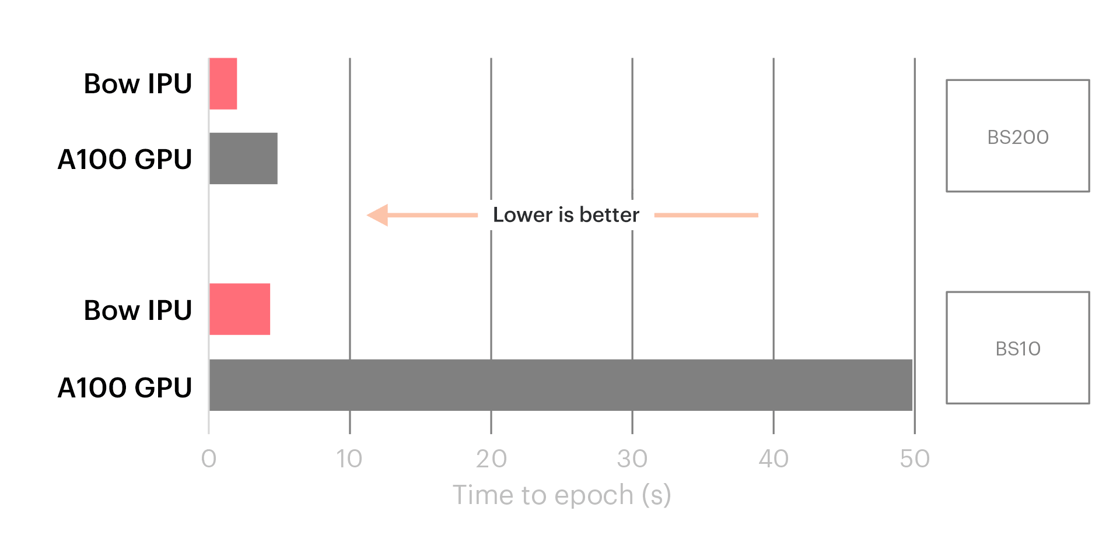
IPUs outperformed GPUs for TGNs, with the difference especially pronounced for common, smaller batch sizes.
이와 마찬가지로 미국 에너지부의 PNNL 연구소는 IPU 시스템을 사용하는 SchNet GNN의 결과 도출 시간이 V100 GPU와 비교해 36배 더 빠르다고 보고했습니다.
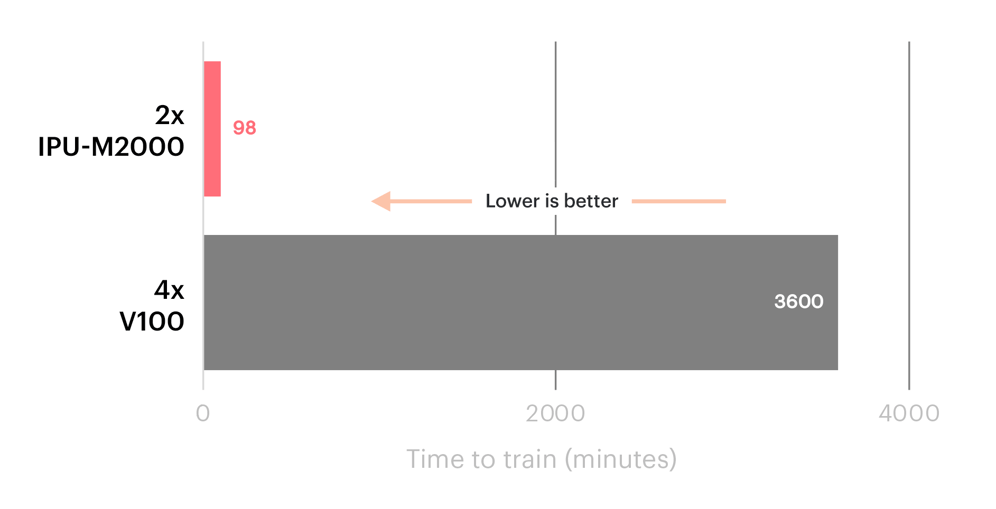
SchNet GNN performance on IPU Classic vs V100 GPUs.
GNN 사용사례에서 확인할 수 있는 중요한 이점 외에도, 조건부 희소성 및 전문가 네트워크와 같은 IPU 친화적인 기법이 점점 연구소를 넘어 보다 광범위한 분야에 적용되고 있습니다.
AI가 지금과 같은 속도로 계속 발전하려면 새로운 기능과 더 높은 수준의 정확성을 제공할 할 뿐 아니라, 차세대 모델을 더 효율적으로 작동할 수 있어야 합니다. 이는 곧 그래프코어가 제공하는 것과 같은 새로운 유형의 시스템 아키텍처가 필요함을 의미합니다.
모델 크기와 복잡성이 점점 증가하면서 매개변수는 몇 년 사이에 수억 개에서 수십억 개로 늘었고, 지금은 수조 개에 달합니다.
이를 통해 텍스트, 음성, 비전 등을 처리할 수 있는 멀티모달 모델을 비롯한 전례없는 기능들이 구현되고 있습니다.
하지만 그 성장 속도가 실리콘의 용량이 따라갈 수 있는 수준을 넘어서고 있습니다. 업계는 지난 몇 년 동안 해당 문제를 해결하기 위해 더 많은 컴퓨팅을 투입하고 있지만 이는 지속 불가능한 해결책입니다.
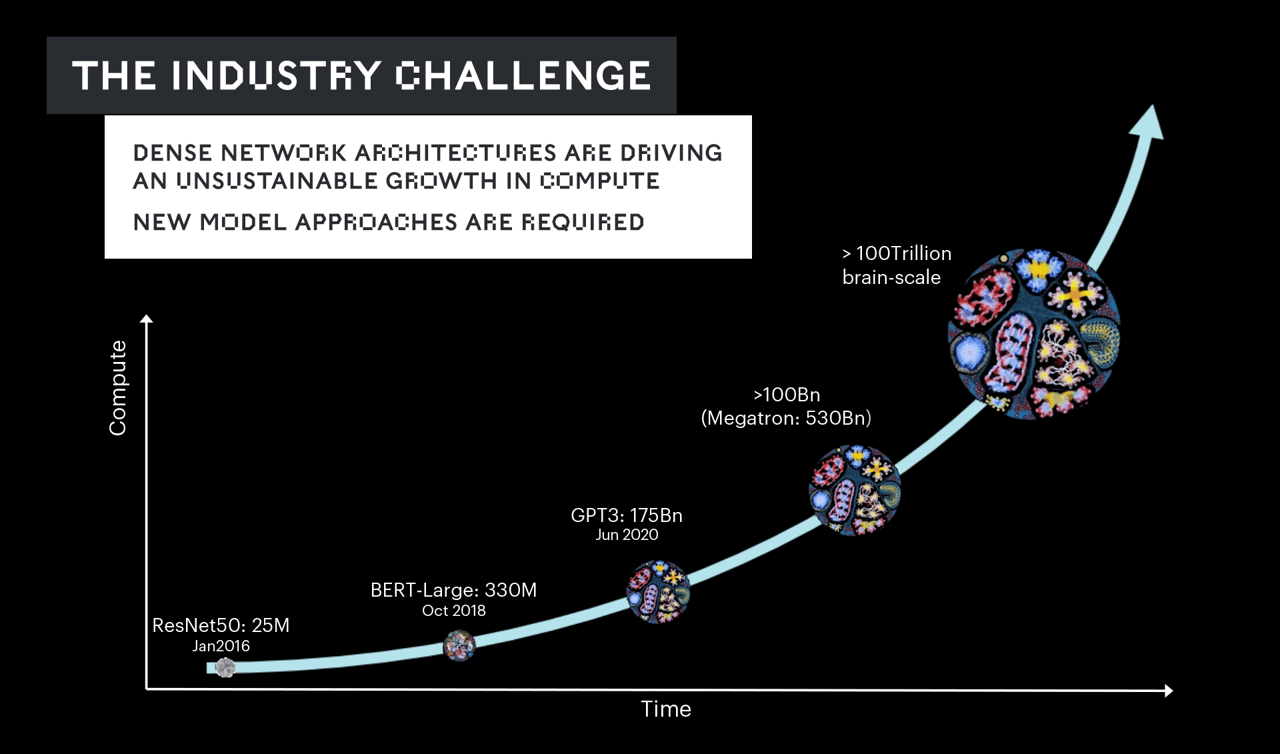
가장 큰 모델을 훈련시키려면 수백만 개의 프로세서를 몇 달 동안이나 쉬지 않고 구동해야 할 뿐 아니라, 수십억 달러 이상의 비용이 들 수 있습니다.
이러한 '리스크'를 피하고 AI의 지속적인 발전을 보장하기 위해서는 IPU와 같은 시스템상에서 진화된 모델을 개발하고 최적화해야 합니다.
이것이 바로 그래프코어가 집중하고 있는 분야이며, 고객 및 파트너와 함께 이미 유의미한 성과를 거두고 있습니다.
그래프코어는 최근 보다 뛰어난 연산 효율을 제공하기 위해 IPU가 지원하는 차세대 기술을 사용하여 알레프 알파(Aleph Alpha)와 함께 대규모 멀티모달 모델을 연구할 계획을 발표했습니다.
앞으로도 대규모 AI 컴퓨팅 시스템의 필요성은 점차 높아질 것으로 보이는데요. IPU의 고도로 차별화된 접근방식을 활용하면 훨씬 비용효율적인 시스템으로 수조 개의 매개변수로 이루어진 거대 모델을 처리할 수 있습니다.
이를 위해 그래프코어는 차세대 IPU 프로세서와 시스템 메모리 및 대용량 스토리지에 대한 새로운 접근법을 활용하는 ‘굿 컴퓨터(The Good Computer)’를 개발중입니다.
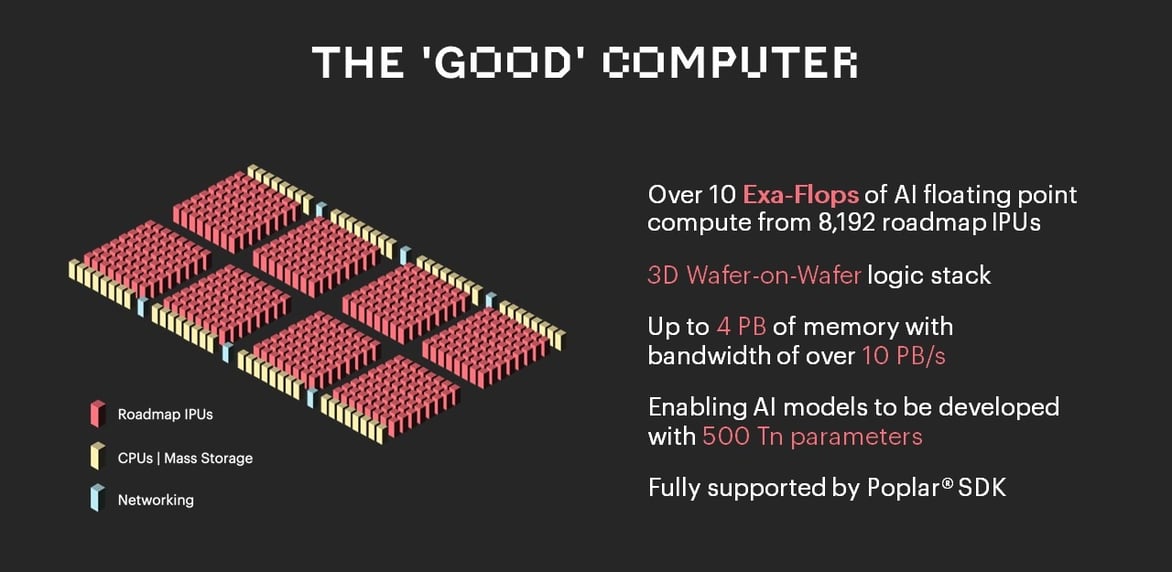 ‘굿 컴퓨터’는 그래프코어 제품 로드맵의 다음 단계 그 이상을 나타내는 것으로, AI 컴퓨팅과 여기에서 비롯되는 여러 유익한 애플리케이션을 개발하기 위한 지속가능한 방법을 의미합니다.
‘굿 컴퓨터’는 그래프코어 제품 로드맵의 다음 단계 그 이상을 나타내는 것으로, AI 컴퓨팅과 여기에서 비롯되는 여러 유익한 애플리케이션을 개발하기 위한 지속가능한 방법을 의미합니다.
시청하기: 초인간적 인지를 위한 컴퓨터 – 사이먼 놀스(Simon Knowles)의 2022 AICAS 발표 영상
공유:

