
Jul 09, 2021 \ Research, University
Jul 09, 2021 \ Research, University
共有:
パリ大学のある研究者がGraphcoreのIPUを使って、宇宙論アプリケーションのためのニューラルネットワーク学習を加速させています。
今回発表された論文では、研究員のBastien Arcelinが、宇宙論における2つのディープラーニングのユースケース(学習したVAE潜在空間からの銀河の画像生成と、
決定論的ディープニューラルネットワークとベイジアンニューラルネットワーク(BNN)を用いた銀河の形状推定)に対するIPUプロセッサの適合性とパフォーマンスについて調査しています。
近い将来、天文学の調査では、これまでにない量の観測データが作成されます。ヴェラ·C·ルービン天文台の「時空間レガシーサーベイ(LSST)」プロジェクトもその一つで、毎晩20テラバイト、10年間の稼働で合計約60ペタバイトのデータが生成されると予想されています。
このような大規模で複雑なデータセットを管理することを目的とした、宇宙論の研究者によるニューラルネットワークの利用が増えています。
しかし、実世界の観測では未知の変数や制御できない変数がとても多いため、この種のデータでニューラルネットワークを学習することは非常に困難になります。
多くのAIアプリケーションと同様に、正確なパラメータを把握して制御できるシミュレーションデータが学習にも最適です。
そしてそのようなデータの量と品質は、LSSTのような測光による銀河調査で記録された実データにできるだけ近いものであることが理想的です。
またこの模擬データは大規模かつ複雑であるため、関連するニューラルネットワークは高速かつ正確である必要があり、アプリケーションによっては認識論的不確実性を正確に特徴づけることができなければなりません。
このような計算面での要求は、「AI専用に設計されたハードウェアは、宇宙論におけるディープラーニングにおいて優れたパフォーマンスを発揮できるのか」という疑問を提起します。
GraphcoreのIPUはグラフ(あらゆるAIアルゴリズムの背景にある基本構造)を効率的に処理するように設計されているので、この理論を検証するための理想的な模範プロセッサとなっています。
今回の研究では、Graphcoreの第1世代チップであるGC2 IPU 1台とNvidia V100 GPU 1台のパフォーマンスが比較されています。
小さなバッチサイズでニューラルネットワークを学習する場合、DNNではIPUがGPUの2倍以上、BNNでは4倍以上の速度で動作することがわかりました。そしてGC2 IPUは、GPUの半分の消費電力でこのパフォーマンスを達成しました。
TensorFlow 1とTensorFlow 2は、統合されたXLAバックエンドを備えたIPUで完全にサポートされているので、すべての実験でTensorFlow 2.1のフレームワークが使用されました。
銀河など、宇宙の起源のシミュレーションに基づくデータは従来、
セルシックのプロファイルのような単純な解析的プロファイルに基づくもので、モデルのバイアスをもたらすリスクを高める、遅い生成技術でした。
ディープラーニングの手法は、データをはるかに高速にシミュレーションできる可能性があります。宇宙論におけるさまざまなアプリケーションにおいて、生成ニューラルネットワークが銀河のモデル化に採用されることが多くなっています(Lanusseおよびその他(2020年)、Regier、McAuliffe、Prabhat(2015年)、Arcelinおよびその他(2021年)など)。
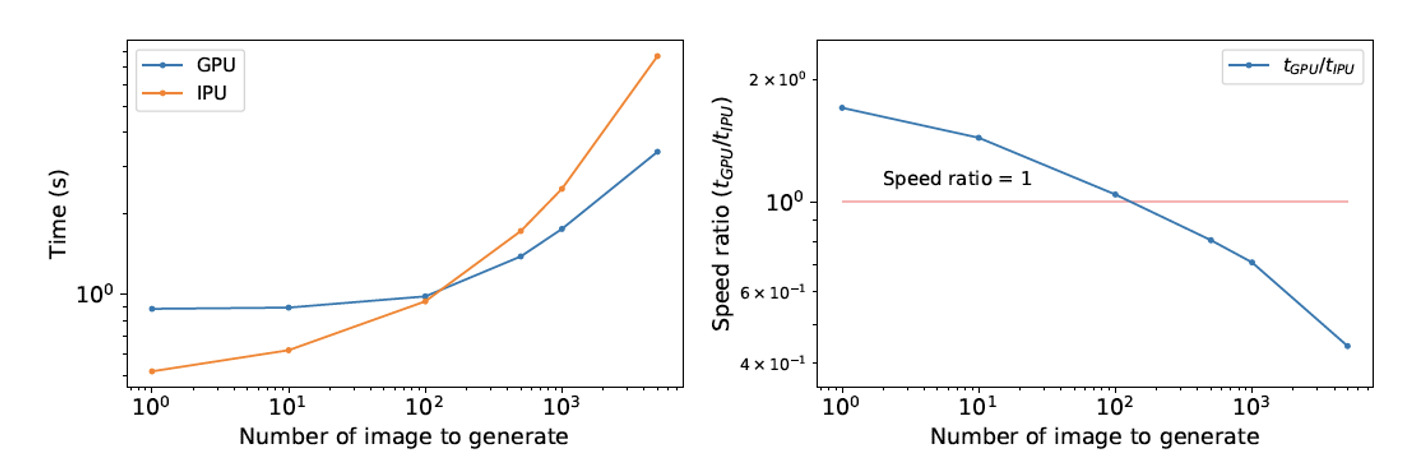
画像は、孤立銀河の画像で学習された変分オートエンコーダ(VAE)の潜在空間分布をサンプリングすることで生成されます。
この場合、画像の小さなバッチを生成するときは、IPUがGPUよりも優れていることがわかります。
このワークロードをGraphcoreの第2世代IPUであるGC200で実行した場合、このプロセッサのオンチップメモリは大幅に拡張されているため、より大きなバッチを生成するときのパフォーマンスが大幅に向上する可能性が高いと考えられます。
次世代の天文学調査では、かつてないほど宇宙の奥深くまで観察することになるため、天体が混合(重複)してしまう確率が高くなります。銀河の一部が覆われていると、銀河の形状を測定するのが難しくなることは明らかです。
銀河の形状を測定する既存の手法では、このような重なり合う天体を正確に測定できないため、今後さらに宇宙の観測を進めていくにつれて新たな技術が必要になってきます。
パリ大学の研究者であるBastien Arcelinは、孤立銀河と混合銀河の形状楕円率のパラメータを測定するために、ディープニューラルネットワークと畳み込み層を用いた新しい技術を開発しています。
1回目の実験は決定論的ニューラルネットワークを用いて、2回目の実験はBNNを用いて行われました。決定論的ネットワークの学習可能なパラメータは、一度学習すると固定値となり、同じ孤立銀河の画像をネットワークに2回入力しても変化しません。これは、重み付け自体を単一の値ではなく、確率分布で割り当てるBNNとは対照的です。つまり、BNNネットワークに同じ画像を2回入力すると、確率分布のサンプリングが2回行われ、2つの微妙に異なる出力が得られるということです。これらの分布を複数回サンプリングすることで、結果の認識論的不確実性を推定できます。
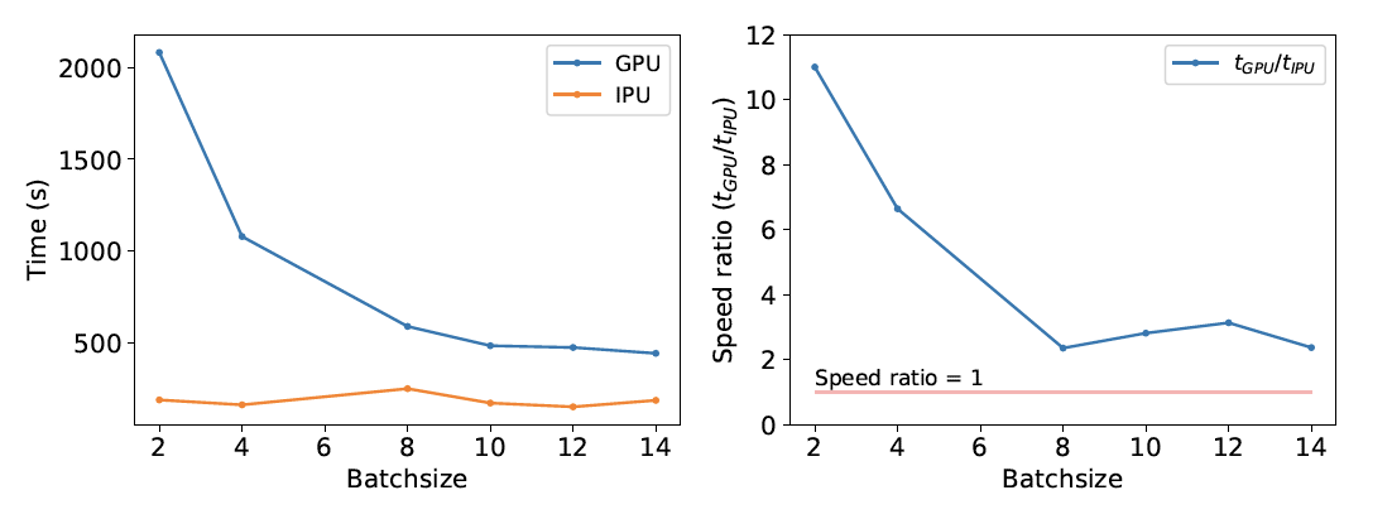
決定論的ニューラルネットワークでは、GPUに比べてGraphcoreのIPUの方が学習時間が短く、特に小さいバッチサイズを使用した場合に顕著です。IPUの技術はすでに、コンピュータビジョンアプリケーションにおける畳み込みニューラルネットワークの効率を上げることで知られているので、これは驚くべきことではありません。
次に、この手法をベイジアンニューラルネットワークでテストしました。ニューラルネットワークの予測に対する信頼度を確立できるかどうかは、宇宙論の研究者にとってとても重要です。研究者はBNNを使って、予測に関連する認識論的不確実性を計算できるので、予測の信頼度を決定するのに役立ちます。認識論的不確実性は大きな測定誤差と強い相関があるからです。
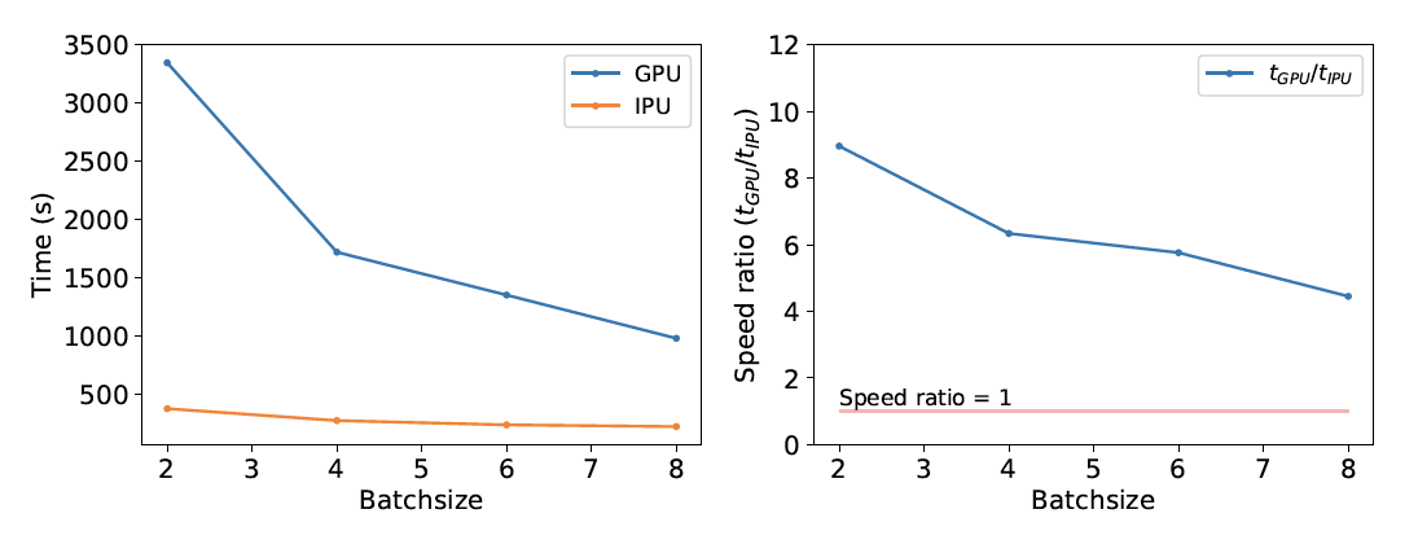
BNNでも、GPUよりもIPUの方が、学習時間が4倍以上も短くなっています。
以上から明らかなように、IPUは銀河の形状パラメータ推定において人工ニューラルネットワークの学習時間を大幅に短縮でき、この研究のように1台のIPUを使用する場合には、小さなバッチサイズで最高のパフォーマンスを発揮します。バッチサイズが大きい場合でも、ネットワークを複数のIPUに分割することでパフォーマンスと効率を向上させることができます。
共有:

