
Oct 22, 2021 \ Product, IPU-POD, Cloud
Oct 22, 2021 \ Product, IPU-POD, Cloud
共有:
IPU-POD128とIPU-POD256は、GraphcoreのAI演算システムを稼働させながらスケールアウトするための最新かつ最大規模の製品で、スケールアウトを前提にゼロから設計されたアーキテクチャの強みとメリットを発揮します。
IPU-POD128では32ペタフロップス、IPU-POD256では64ペタフロップスの強力なAI演算機能を備えるこれらの新製品によって、Graphcoreのシステムはスーパーコンピュータの領域にまでさらに拡大されます。
クラウドハイパースケーラーや国立の科学計算研究所、大企業のAIラボなどに最適なこれらの新型IPU-PODを利用することで、システム全体で大規模なモデルの学習を高速化できるほか、システムをより小さく柔軟なvPODに分割することによって、より多くの開発者がIPUにアクセスできるようにもなります。
IPU-POD128とIPU-POD256はどちらも本日より、ATOSをはじめとするシステムインテグレーターのパートナー企業からお客様に出荷されます。また、クラウドでの購入も可能です。
一般的なモデルを実行した初期の結果では、優れた学習性能と非常に効率的なスケーリングが示されており、今後のソフトウェアの改良によってさらなる性能の向上が期待されます。
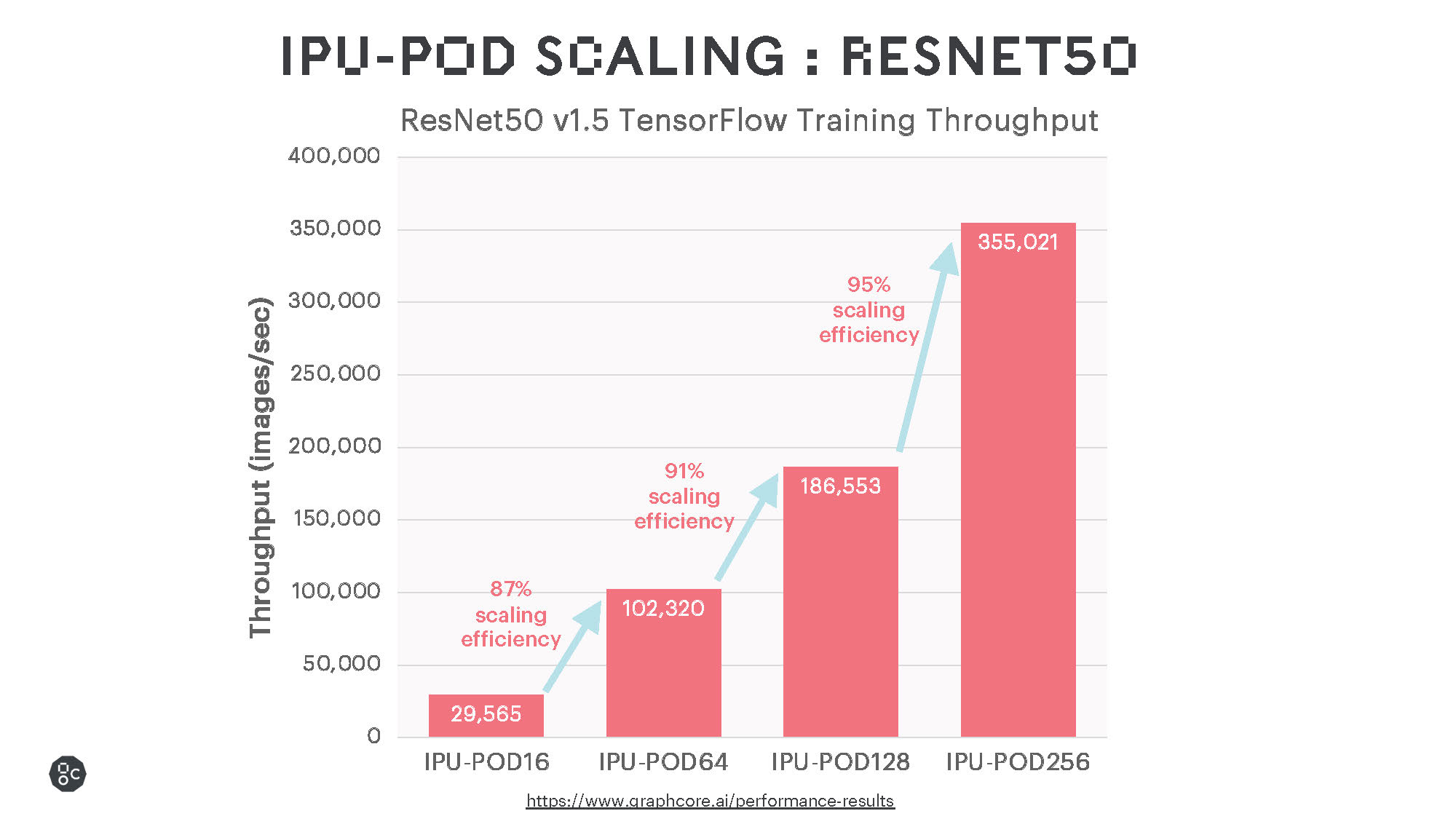
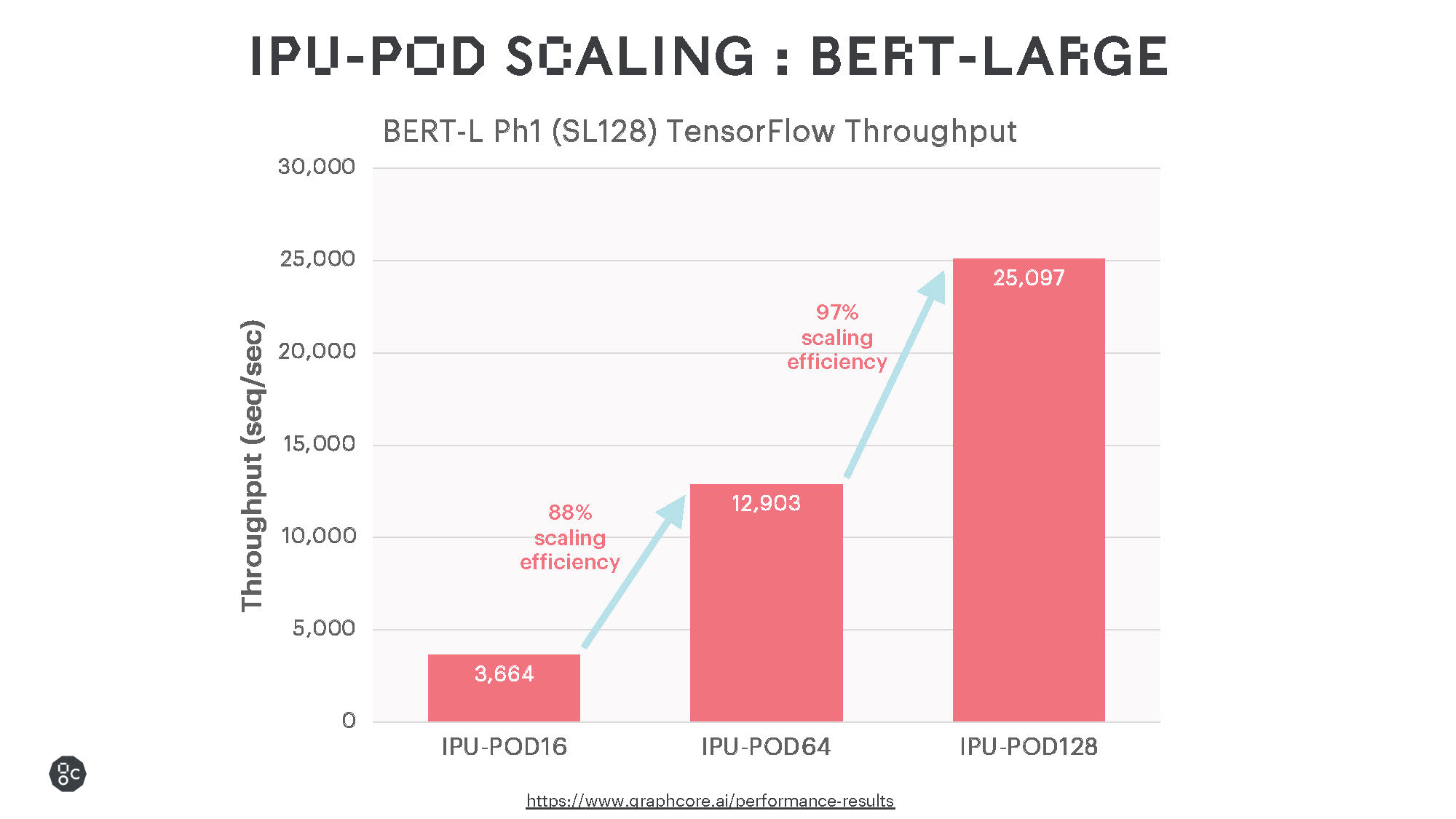
インテリジェント・プロセッシング・ユニット(IPU)は、内蔵されたオンプロセッサメモリにより、BERTやResNet-50のような従来の大規模なMatMulモデルに対して優れた性能を発揮するのはもちろん、sparse multiplicationやより細かい計算をより効率的に行える、より一般的なタイプの計算もサポートしています。EfficientNetファミリーのモデルはこの恩恵を大きく受けますが、グラフニューラルネットワーク(GNN)など、ニューラルネットワークではない様々な機械学習モデルも同様です。
Atosは、世界中の顧客にIPU-POD128およびIPU-POD256システムの導入を進める、Graphcoreの数多くのパートナーのうちの一社です。
AtosのHPC&Quantum部門の責任者であるAgnès Boudot上級副社長は、「Atos ThinkAIのポートフォリオにGraphcoreのIPU-POD128システムとIPU-POD256システムを加えることで、学術研究や金融、医療、通信、消費者インターネットなどの多くの分野において、当社のお客様がより大規模で革新的なAIモデルをより短期間で探求し、展開できると期待しています」と述べています。
韓国の大手テクノロジー企業であるKTも、IPU-POD128を最初に導入したお客様のうちの一社ですが、すでに演算能力の向上によるメリットが生まれています。
KTは、当社IDC内の高密度AI専用ゾーンにおいて、GraphcoreのIPUを活用した「ハイパースケールAIサービス」を韓国で初めて提供しています。
現在ではかなりの数の企業や研究機関が、前述のサービスを研究やPoCに利用したり、IPU上でテストを行ったりしています。
「超大規模AI HPC環境市場の高まる需要に絶え間なく応えるために、私たちはGraphcoreと提携して当社のIPU-POD64をIPU-POD128にアップグレードすることで、お客様への『ハイパースケールAIサービス』の提供を拡充しています。
今回のアップグレードによって当社のAI演算の規模は32ペタフロップスに拡大しますので、より多様なお客様が大規模なAIモデルの学習や推論に、KTが誇る最先端のAI演算を利用できるようになると期待しています」と、クラウド/DXビジネスユニットのMihee Lee上級副社長は語ります。
IPU-POD128とIPU-POD256の発売は、AIに関する取り組みのあらゆる段階でお客様にサービスを提供するGraphcoreのコミットメントを明確に示すものです。
IPU-POD16はこれまで同様、「探求する」ことに最適なプラットフォームであるのに対し、IPU-POD64はAI演算能力を「構築する」ことを目指すお客様向け、そして今回のIPU-POD128とIPU-POD256は、より速く、より大きく「成長する」必要のあるお客様向けの製品です。
他のIPU-PODシステムと同様にAI演算とサーバーが分離されているIPU-POD128とIPU-POD256は、異なるAI作業負荷に対して最大の性能を発揮するように最適化することができ、総所有コスト(TCO)の効率化を最大限に高めます。たとえば、NLPに特化したシステムではわずか2台のサーバーしか使用できませんが、コンピュータビジョンタスクのようなデータ量の多いタスクでは8台のサーバーのセットアップを活用できます。
さらに、Graphcoreが最近発表したストレージパートナーの技術を用いて、特定のAI作業負荷に合わせてシステムのストレージを最適化することもできます。
Graphcoreの演算性能をIPU-POD128やIPU-POD256までスケールアップすることは、ハードウェアとソフトウェアの両面で採用されている多くの実現技術によって可能になっています。
Graphcoreのあらゆるハードウェアと同様に、IPU-POD128とIPU-POD256はPoplarのソフトウェアスタックと共同設計されています。
当社のスケールアウトシステムを実現する機能は、最新のSDK 2.3を含む複数のPoplarソフトウェアリリースで導入されています。ここではIPU-POD128とIPU-POD256に特に関連のあるものを紹介していますが、この他にも多数の導入事例があります。
Graphcore Communication Library(GCL):IPU間の通信や同期を管理するためのソフトウェアライブラリです。IPUシステムの高性能なスケールアウトを可能にするように設計されています。コンパイル時にプログラムを実行するIPUの数を指定でき、複数のIPU-PODに分散させることができます。プログラムはGCDを利用して、IPU-POD間で自動的かつ透過的に実行されるので、開発者に追加のコストや複雑さを強いることなく性能とスループットの向上を実現します。
PopRunとPopDist:開発者はPopRunとPopDistを使用して、複数のIPU-PODシステム間でアプリケーションを実行できます。
PopRunはIPU-PODシステム上で分散アプリケーションを起動するためのコマンドラインユーティリティであり、Poplar分散構成ライブラリ(PopDist)は、開発者がアプリケーションの分散実行を準備するために使用できる一連のAPIを提供します。
IPU-POD128やIPU-POD256のような大規模システムを使用する場合、相互に接続された別のIPU-PODにあるホストサーバー上で、PopRunが複数のインスタンスを自動的に起動します。アプリケーションのタイプによっては、複数のインスタンスを起動することで性能が向上します。開発者はPopRunを使用して、ホストサーバー上で複数のインスタンスを起動することができます。またNUMAをサポートしているので、NUMAノードを最適に配置することもできます。
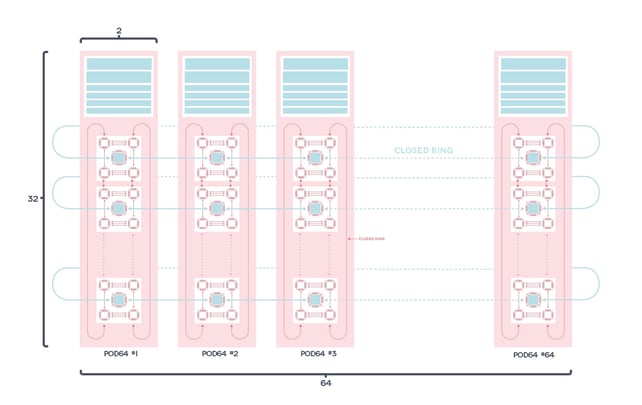
IPU-POD128とIPU-POD256の量産開始はデータセンターにおけるIPUシステムのスケーリングにおいて、次の大きな進歩をもたらします。
マルチラックシステムでAI演算を実現するうえで、GraphcoreのIPU-Fabricがある程度貢献しています。IPU-Fabricは、AI向けに最適化された一連のインフラストラクチャ技術で、IPU間のシームレスで高性能な通信を実現するように設計されています。
ラック内部のIPU通信には、すでにIPU-POD16やIPU-POD64などで採用されている64GB/sのIPU-Linksを使用しています。
Graphcoreの製品の中でIPU-POD128とIPU-POD256は、IPU-Linksを通常の100Gbイーサネット上のトンネリングを使って拡張する、水平方向のラック間接続であるGateway Linksを採用した最初の製品です。
通信は、各IPU-M2000に搭載されたIPU-Gatewayによって管理されます。接続は、標準的な100Gbスイッチに対応する、IPU-M2000のデュアルQSFP/OSFP IPU-GWコネクタを介して行われます。
共有:

