
Jun 28, 2021 \ Computer Vision, Research
Jun 28, 2021 \ Computer Vision, Research
共有:
Graphcore Researchは、同社が開発した新技術 「Proxy Norm」が、いかにしてメモリ効率の高い畳み込みニューラルネットワークの学習に道を開くかについて説明しています。Graphcoreの新しい論文によると、Proxy Normはバッチ正規化の利点を損なうことなく、これまでは非効率的な実行につながっていたバッチ依存性という厄介な問題を排除できる技術です。Proxy Normは、機械学習モデルの規模が増大し、データセットが大きくなり続ける中で、将来的にAIエンジニアが実行効率を確保するのに役立つでしょう。
ニューラルネットワークを大規模で深いモデルにスケールアップする上で、正規化はとても重要です。正規化の範囲はもともと入力処理に限定されていましたが(Lecunおよびその他、1998年)、ネットワーク全体で中間アクティベーションを正規化して維持するバッチ正規化(IoffeおよびSzegedy、2015年)という技術が導入されてから、さらにレベルアップしました。
Batch Normが課す具体的な正規化は、チャンネル単位の正規化です。具体的にBatch Normでは、チャンネル単位の平均値を引き、チャンネル単位の標準偏差で割ることで中間アクティベーションを正規化しています。ここで注目すべき点は、Batch Normはニューラルネットワークの表現性を変えることなく、チャンネル単位の正規化を実現していることです。つまり、バッチ正規化されたネットワークの表現性は、正規化されていないネットワークの表現性と同じなのです。これらの2つの特性、すなわちチャンネル単位の正規化と表現性の維持は、どちらも有益であることがわかります。
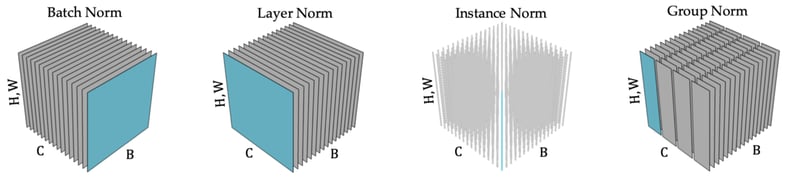
しかしBatch Normには、バッチ依存性という同じくらい重大で厄介な問題があります。データセット全体のチャンネル単位の平均と分散は容易には計算できないので、Batch Normは現在のミニバッチをデータセット全体の代理とみなすことで、これらの統計値を近似します(図1を参照)。Batch Normの計算にミニバッチ統計値が使用されることを考慮すると、ニューラルネットワークによってある入力に関連付けられる出力は、その入力だけでなく、ミニバッチ内のその他すべての入力にも依存します。言い換えれば、フルバッチ統計値をミニバッチ統計値で近似することで、ニューラルネットワークの計算にバッチ依存性が生じるのです。
それでは、なぜチャンネル単位の正規化や表現性の維持が有益なのか、そしてなぜバッチ依存性が厄介な問題なのかを理解するために、Batch Normについて詳しく見ていきましょう。その後で、弊社の論文「Proxy-Normalizing Activations to Match Batch Normalization while Removing Batch Dependence(バッチ依存性を排除しながらバッチ正規化と同等にアクティベーションをプロキシ正規化する)」で紹介したGraphcore Researchの新技術「Proxy Norm」をご紹介し、Proxy Normを使うことで、Batch Normの2つの利点を維持しつつ、バッチ依存性を排除できることについてご紹介します。
前述したように、Batch Normは各層において、非線形性に「近い」、チャンネル単位で正規化された中間アクティベーションを維持します。このチャンネル単位の正規化には、次のような2つの利点があります。
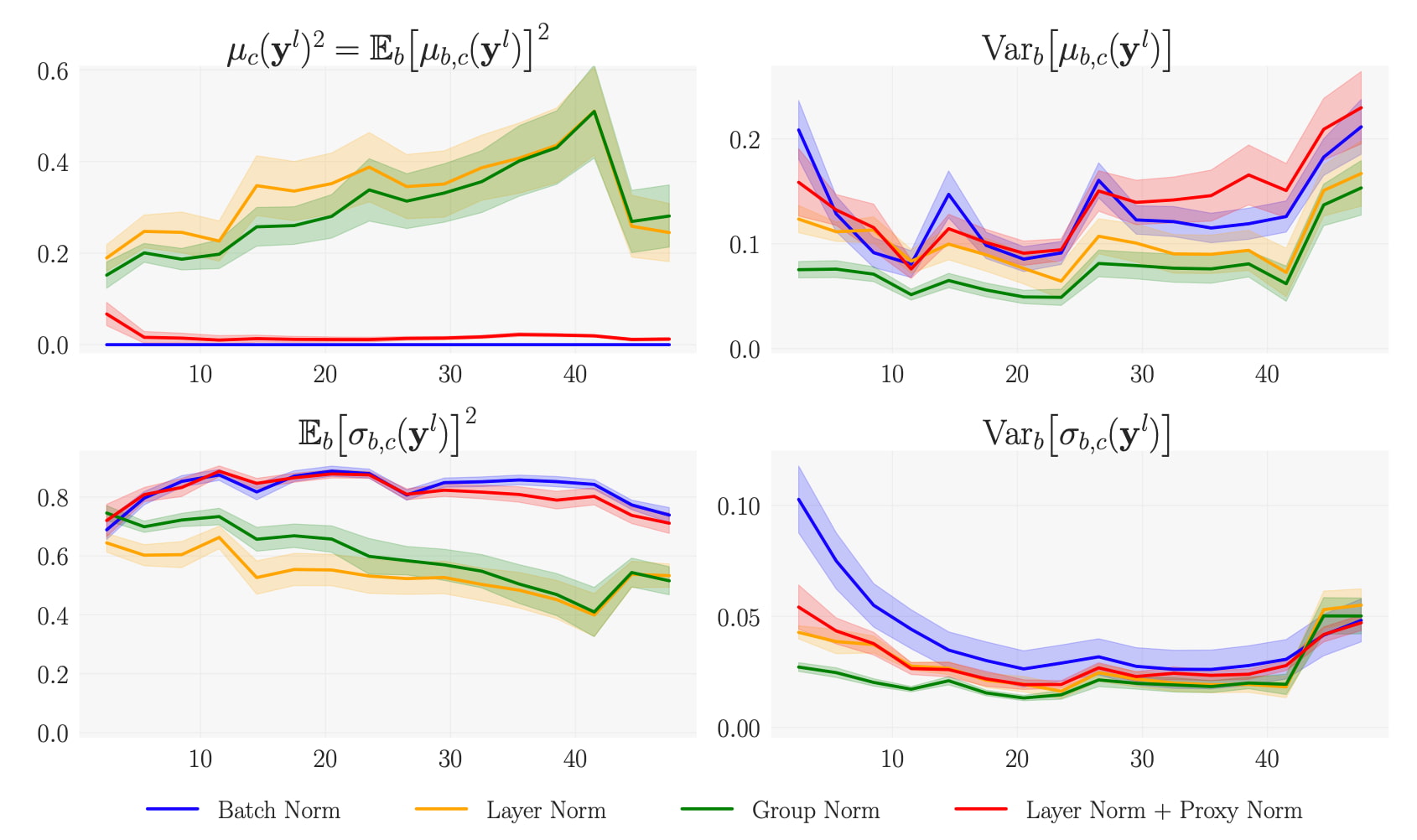
つまり、チャンネル単位の正規化によってニューラルネットワークの全能力を効果的に活用できるのです。しかしBatch Normに代わる原型的なバッチに依存しない方法では、この利点は生かされません(図1を参照)。実際に、Instance Normではチャンネル単位の正規化が維持されていますが、Layer NormやGroup Normでは維持されません。図2の左上のプロットでは、Layer NormとGroup Normを使ったチャンネル単位の二乗平均値が無視できない値になっています。
前述したように、Batch Normによるチャンネル単位の正規化では、ニューラルネットワークの表現性の変化は犠牲になりません。つまり、Batch Normのスケールとシフトのパラメータを適切に選択すれば、正規化されていないネットワークは(フルバッチ設定で)バッチ正規化されたネットワークとして同等に表現されるということです。逆に、畳み込み重みづけと偏りを適切に選択すれば、(フルバッチ設定で)バッチ正規化されたネットワークは正規化されていないネットワークと同等に表現されます。つまりBatch Normは、ニューラルネットワークの解空間を単純に再パラメータ化したものです。
この表現性の維持がBatch Normの第2の利点です。このような表現性の維持がなぜ有益なのか。それを理解するためには、Batch Normに代わるバッチに依存しない表現性の変化がなぜ有害なのかを理解することが役立ちます。Instance NormとGroup Normの場合、図2の右2つのサブプロットに見られるように、表現性の変化の症状として、インスタンスの平均値と標準偏差の分散が欠如していることがわかります。このようにインスタンスの統計値に分散が欠如していることは、ニューラルネットワークの深い層で高レベルの概念を表現することと相いれない傾向があるため、学習には有害になります。
Batch Normのバッチ依存性の主な症状は、各ミニバッチの異なる入力をランダムに選択することに起因するノイズの存在です。このノイズはBatch Normの層の間で伝播し、フルバッチ統計値がミニバッチ統計値で近似されたときに、Batch Normの各層でその傾向が「助長」されます。そのため、ミニバッチが小さいほどノイズが強くなります。 この現象はBatch Normの特定の正則化につながり(Luoおよびその他、2019年)、その強さはノイズの振幅に依存し、その結果ミニバッチのサイズに依存します。
残念ながら、この正則化をコントロールすることは容易ではありません。この正則化の強さを抑えることが目的の場合は、ミニバッチのサイズを大きくするしかありません。Batch Normは最適なパフォーマンスを実現するために、タスクと必要な正則化の強さに応じてミニバッチサイズの下限を強制します。「計算」ミニバッチのサイズがこの下限を下回る場合、最適なパフォーマンスを維持するには、複数のワーカー間で統計値の「高価な」同期を行い、「計算」のミニバッチよりも大きな「正規化」のミニバッチを得る必要があります(Yinおよびその他、2018年)。その結果、バッチ依存性が原因で実行の非効率性という最大の問題が発生します。
GraphcoreのIPUを使用すると、メモリの制約が厳しくなるのと引き換えに、IPUによって加速性と省エネ性が高まるので、このような問題が解決されて実際に違いが生まれます。たとえローカルメモリへの依存度が低いアクセラレータを代用できても、この問題は将来、極めて重要になる可能性があります。データセットの規模が大きくなればなるほど、より大きなモデルを使用することによって、より厳しいメモリ制約が課せられることは想像に難くありません。また一定のモデルサイズでより大きなデータセットを使用する場合は、必要な正則化が少なくなります。その結果、Batch Normなどのバッチ依存のノルムを使用するときに、最適なパフォーマンスを保証するために必要な「正規化」のミニバッチがますます大きくなります。
それでは、Batch Normの利点を維持しつつ、バッチ依存性を排除するにはどうすればよいのでしょうか。
Batch Normの2つの利点(チャンネル単位の正規化と表現性の維持)は、Batch Normに代わる原型的なバッチに依存しない方法では両立できません。一方では、Layer Normは表現性を維持するのに適していますが、チャンネル単位の非正規化が犠牲になります。他方では、Instance Normではチャンネル単位の正規化が保証されますが、その代償として表現性が大きく変化してしまいます。Group Normは、Layer Normの問題とInstance Normの問題の妥協点としては優れていますが、それでも本来の目的は達成できません。つまり、Batch Normに代わる原型的なバッチに依存しない方法はすべて、パフォーマンスの低下を招きます。
この問題を解決するためには、チャンネル単位の非正規化を回避しながら同時に表現性を維持できる、バッチに依存しない正規化が必要です。この2つの要件をより正確に把握するために、次のことに注目しましょう。
このような見解をもとに、新しい技術Proxy Normが設計されています。Proxy Normは正規化演算の出力を、チャンネル単位で正規化された状態に近いと想定されるガウス「プロキシ」変数に同化します。このガウスプロキシは実際のアクティベーションと同じ2つの演算、すなわち、同じ学習可能なアフィン変換と同じアクティベーション関数に入力されます。これら2つの演算の後、最終的にこのプロキシの平均と分散が、実際のアクティベーション自体を正規化するために使用されます。これを図3で説明します。

Proxy Normは、学習可能なアフィン変換とアクティベーション関数という2つのチャンネル単位の非正規化の主な発生源を補いながら、表現性を維持できます。それに基づいて、Proxy NormとLayer Norm、またはGroup Normと少数のグループを組み合わせた、バッチに依存しない正規化のアプローチを採用しました。図2に示すように、このバッチに依存しない正規化のアプローチでは、チャンネル単位の正規化が維持されつつ、表現性の変化は最小限に抑えられます。このアプローチを使ってBatch Normの利点を維持しつつ、バッチ依存性を排除しているのです。
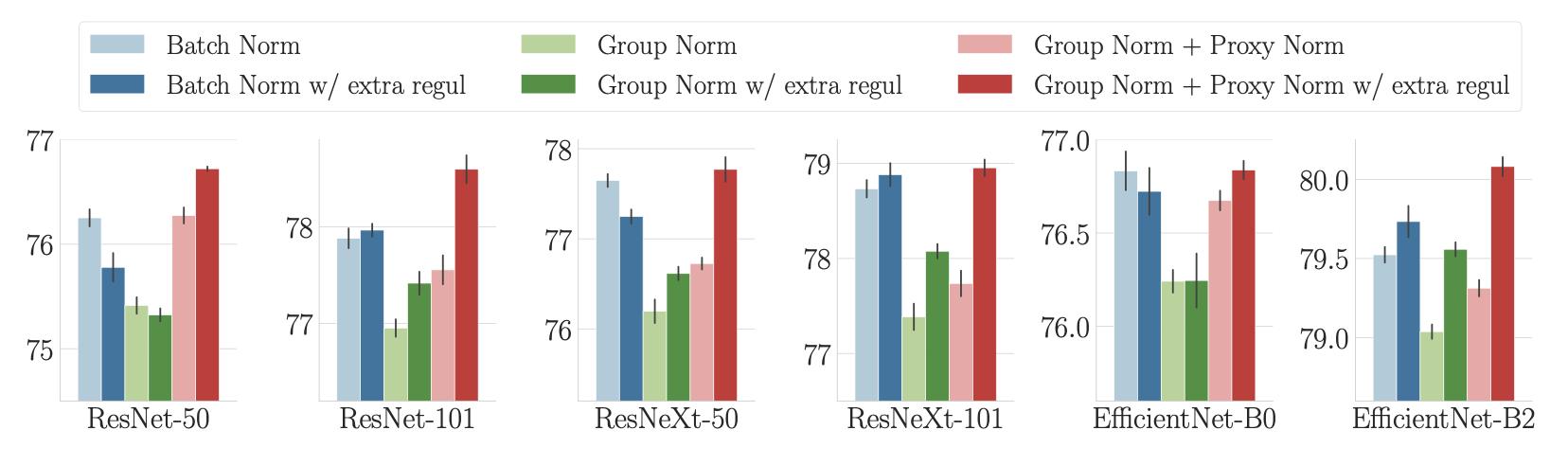
次の問題は、このアプローチが実用的なパフォーマンスの向上につながるかどうかです。Batch Normとバッチに依存しないアプローチを比較するときには、Batch Normを用いることのバッチ依存性から追加で生じる正則化を適切に考慮するために、特別な注意が必要です。そのために、実験のたびに追加の正則化を含めることで、この正則化の効果を「差し引いて」います。
図4に示すように、そのような特別な注意を払った場合、バッチに依存しないアプローチのImageNetパフォーマンスは、様々なモデルのタイプとサイズにおいて、一貫してBatch Normと一致しているか、またはそれを上回っています(EfficientNetのバリアントは、関連するブログ投稿[リンクを追加]と論文で紹介されています)。つまり、バッチに依存しないアプローチは、挙動だけでなくパフォーマンスにおいてもBatch Normに匹敵するということです。
私たちの分析の副産物として、効率的な正規化はImageNetのパフォーマンスの向上に必要である一方、それには適切な正規化も必要であることがわかりました。はるかに大規模なデータセットでは、効率的な正規化を行えばそれだけで十分であり、正規化の必要性は低くなると考えられます(Kolesnikovおよびその他、2020年、Brockおよびその他、2021年)。
今回は、畳み込みニューラルネットワークにおける正規化の内部の動きについて掘り下げて説明しました。私たちが得たのは、効率的な正規化とは(i)チャンネル単位の正規化を維持すること、(ii)表現性を維持することであるとの理論的かつ実験的な証拠です。Batch Normではこの2つの特性は維持されますが、バッチ依存性という厄介な問題を同時に抱えています。
Batch Normに代わる原型的なバッチに依存しない方法を検討したところ、チャンネル単位の正規化と表現性の維持を両立するのは難しいことがわかりました。そこで私たちは、チャンネル単位の正規化を維持しながら表現性も維持できる新しい技術、「Proxy Norm」を作りました。そしてProxy NormとLayer Norm、またはGroup Normと少数のグループを組み合わせた、バッチに依存しない正規化のアプローチを採用しました。このようなアプローチは、バッチ非依存性を常に維持しながら、挙動とパフォーマンスの両方において一貫してBatch Normに匹敵することがわかりました。
このアプローチは、畳み込みニューラルネットワークをより効率的に学習するための道を開くものです。このメモリ効率は、ローカルメモリを活用して実行効率を高めるGraphcoreのIPUのようなアクセラレータにとって、とても大きな競争力となります。長期的には、代替ハードウェアであっても、このメモリ効率が極めて重要になると考えられます。
共有:

