
Jun 14, 2022 \ Machine Learning
Jun 14, 2022 \ Machine Learning
共有:
Michael Bronstein氏は、オックスフォード大学のDeepMind教授(AI)、Twitterのグラフラーニング研究責任者です。この記事は、Bronstein氏のブログに最初に掲載されました。また、TwitterのEmanuele Rossi氏、GraphcoreのDaniel Justusと共同で執筆しています。
相互作用するエンティティの複雑なシステムを扱う多くの応用で、データはグラフとして構造化されます。近年、グラフ構造化データ、特にグラフニューラルネットワーク(GNN)への機械学習の応用により、人気が大きく高まっています。
GNNアーキテクチャの大部分は、グラフが固定されていることを前提としています。しかし、この仮定は単純すぎることがよくあります。多くの応用では、基盤となるシステムが動的であるため、グラフは時間とともに変化します。例えば、ソーシャルネットワークや推薦システムでは, コンテンツに対してユーザーが反応していることを示すグラフがリアルタイムで変化することがあります。最近、この動的グラフを処理できるGNNアーキテクチャが、時間的グラフネットワーク(TGN)[1]など、いくつか開発されました。
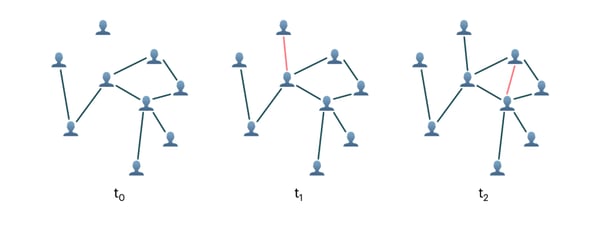
タイムスタンプ t1 と t2で新しいエッジを取得することにより、人と人の相互作用のグラフが動的に変化
このブログでは、さまざまなサイズの動的グラフへのTGNの応用を探り、このクラスのモデルの演算の複雑さを調べていきます。GraphcoreのBowインテリジェンス・プロセッシング・ユニット(IPU)を使用して、TGNを演算することで、なぜIPUのアーキテクチャがこの複雑さに対処するのに最適で、単一のIPUプロセッサをNVIDIA A100 GPUと比較して桁違いのスピードアップになることを示しています。
TGNアーキテクチャには、2つの主要な構成要素があります。まず、ノード埋め込みは、旧式のグラフニューラルネットワークアーキテクチャを介して生成されます。ここでは、単層グラフアテンションネットワークとして実装されています [2]。さらに、TGNは、各ノードの過去のすべての相互作用を要約したメモリを保持します。このストレージには、まばらな読み取り/書き込み操作でアクセスされ、ゲート付き回帰型ユニット(GRU)を使用して新しい相互作用で更新されます[3]。
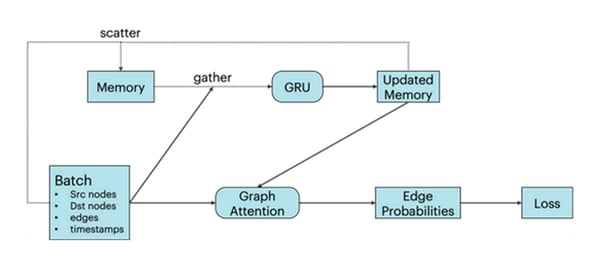
TGNモデルアーキテクチャ:下の行は単一のメッセージパッシングステップのあるGNN、上の行はグラフの各ノードの追加メモリ
ここでは、新しいエッジを取得することで時間とともに変化するグラフに焦点を当てます。この場合、ノードのメモリには、このノードをターゲットとするすべてのエッジと、それぞれの宛先ノードに関する情報が含まれています。間接的な寄与を通じて、ノードに付与されたメモリは、ノードに関する情報を遠くに保持することもできるため、グラフアテンションネットワークの追加の層が不要になります。
最初に、ウィキペディアの記事とユーザーの2部グラフであるJODIE Wikipediaデータセット[4]でTGNを実験します。ここでは、ユーザーと記事の間の各エッジは、ユーザーによる記事の編集です。グラフは、9,227ノード(8,227人のユーザーと1,000件の記事)とタイムスタンプ付きの157,474エッジで構成されています。エッジには、編集を説明する172次元のLIWC特徴ベクトル [5] の注釈があります。
実験中、エッジは最初に切断されたノードのセットにバッチごとに挿入されます。モデルは、真のエッジとランダムにサンプリングされた負のエッジの対照的な損失を使用して学習されます。検証結果は、ランダムにサンプリングされた負のエッジ上で真のエッジを識別する確率として報告されます。
直感的には、大きいバッチサイズは推論だけでなく学習にも悪影響がみられています。ノードのメモリとグラフの連結性はどちらも、完全なバッチが処理されなければ更新されません。したがって、単一のバッチ内の後のイベントは、バッチ内の前のイベントを認識しないため、古い情報に依存する可能性があります。実際に、バッチサイズが大きいとタスクの性能に悪影響が出ることがわかります。
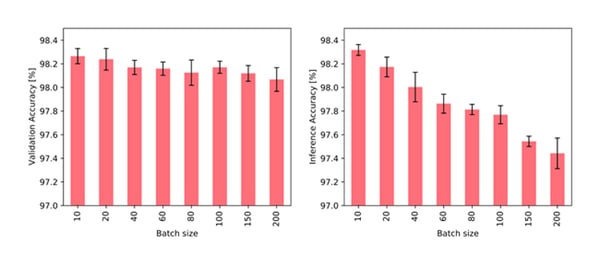
さまざまなバッチサイズでトレーニングして10の固定バッチサイズで検証する場合(左)と、10の固定バッチサイズでトレーニングしてさまざまなバッチサイズで検証する場合(右)のJODIE/WikipediaデータでのTGNの精度
とはいえ、小さなバッチを使用すると、トレーニング中および推論中に高スループットを達成するための高速メモリアクセスの重要性が強調されます。そのため、大容量のプロセッサ内メモリを備えたIPUでは、バッチサイズが小さいGPUよりもスループットが上昇しています。特に、10のバッチサイズを使用すると、TGNはIPUで約11倍速くトレーニングでき、200の大きなバッチサイズでも、IPUで約3倍速くトレーニングできます。
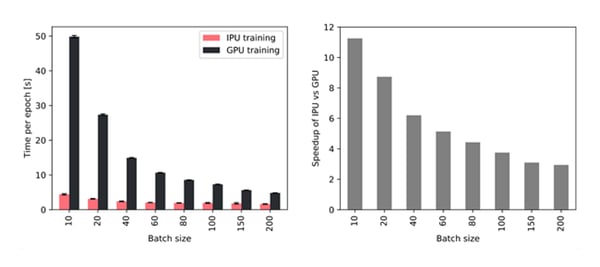
Throughput improvement for different batch sizes when using a single IPU out of a Bow2000 IPU system compared to an NVIDIA A100 GPU.
グラフコアのIPUでのTGNトレーニングのスループット上昇をよりよく理解するために、TGNの主要な操作でさまざまなハードウェアプラットフォームが費やした時間を調査しました。GPUに費やされる時間は、IPUでより効率的に実行される2つの操作であるアテンションモジュールとGRUによって占有されていることがわかります。さらに、すべての処理を通じて、IPUは小さなバッチサイズをはるかに効率的に処理することができます。
特に、IPUの優位性は、より小さく、より断片化されたメモリ操作で高まることがわかります。より一般的には、演算アクセスとメモリアクセスが異種である場合、IPUアーキテクチャはGPUよりも大きな優位性を示すと結論付けることができます。
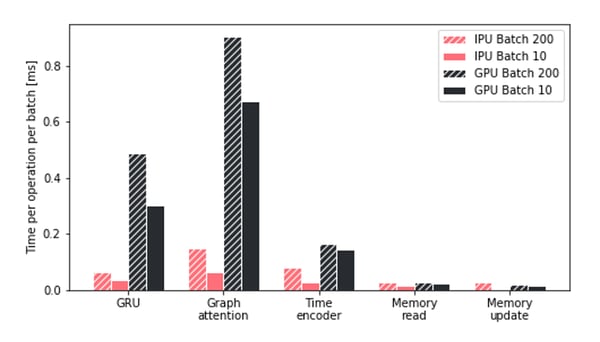
バッチサイズが異なるIPUおよびGPUでのTGNの主要な操作の時間比較
デフォルト構成のTGNモデルは、約260,000のパラメータを備えた比較的軽量なものですが、モデルを大きなグラフに適用する場合、ほとんどのIPUプロセッサ内メモリはノードメモリで使用されます。ただし、アクセスがまばらであるため、このテンソルを外部メモリに移動できます。この場合、プロセッサ内メモリの使用率はグラフのサイズに依存しません。
TGNアーキテクチャを大きなグラフでテストするために、1,550万人のTwitterユーザー、2億6,100万人のフォローを含む匿名化されたグラフに適用します[6]。エッジには、日付順の728の異なるタイムスタンプが割り当てられますが、フォローが発生した実際の日付に関する情報は提供されません。このデータセットにはノードまたはエッジの特徴が存在しないため、モデルはグラフトポロジと時間的発展に完全に依存して新しいリンクを予測します。
大量のデータにより、単一の負のサンプルと比較した場合に正のエッジを識別するタスクが単純になりすぎるため、検証指標として、ランダムにサンプリングされた1,000の負のエッジの中から真のエッジの平均逆順位(MRR)を選択します。さらに、データセットサイズを大きくすると、モデルの性能には、隠れたサイズを大きくすることでメリットがあることがわかります。特定のデータについて、精度とスループットの間の最適な点として、潜在的なサイズ256を識別します。
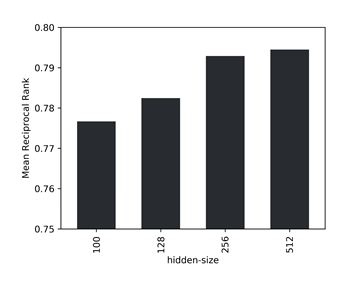
モデルのさまざまな隠れたサイズに対する、1000の負のサンプル間の平均逆順位
ノードメモリに外部メモリを使用すると、スループットが約2分の1に減少します。ただし、さまざまなサイズの誘導部分グラフと、Twitterグラフのノード数10倍の合成データセットおよびランダムな連結性を用いて、スループットがグラフのサイズにほとんど依存していないことを示しています。IPUでこの手法を使用すると、TGNはほぼどのようなグラフサイズにでも適用でき、トレーニング中および推論中に高いスループットを維持しながら、使用可能なホストメモリの量で制限されるだけです。
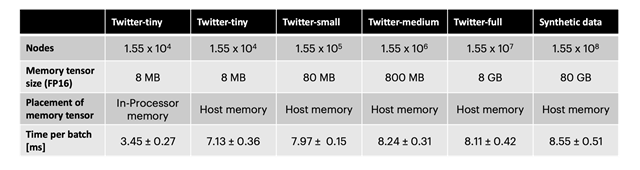
さまざまなグラフサイズで隠れた256のサイズのTGNをトレーニングする際の、サイズ256のバッチあたりの時間。Twitter小はJODIE/Wikipediaデータセットと同じサイズ
以前に繰り返し指摘したように、グラフ機械学習モデルを実装するためのハードウェアの選択は重要ですが、見過ごされがちな問題です。 特に研究コミュニティでは、基盤となるハードウェアを抽象化するクラウドコンピューティングサービスの可用性が、この点で特定の「怠惰」につながります。 しかし、リアルタイムのレイテンシ要件を持つ大規模なデータセットで動作するシステムを実装する場合、ハードウェアの考慮事項を簡単に考慮することができなくなります。 私たちの研究によってこの重要なトピックがより多くの関心を集め、グラフ機械学習アプリケーションのより効率的なアルゴリズムとハードウェアアーキテクチャへの道が開かれることを願っています。
[1] E. Rossi et al., Temporal graph networks for deep learning on dynamic graphs (2020) arXiv:2006.10637. ブログ記事もご参照ください。
[2] P. Veličković, et al., Graph attention networks (2018) ICLR.
[3] K. Cho et al., On the properties of neural machine translation: Encoder-Decoder approaches (2014), arXiv:1409.1259.
[4] S. Kumar et al., Predicting dynamic embedding trajectory in temporal interaction networks (2019) KDD.
[5] J. W. Pennebaker et al., Linguistic inquiry and word count: LIWC 2001 (2001). Mahwah: Lawrence Erlbaum Associates 71.
[6] A. El-Kishky et al., kNN-Embed: Locally smoothed embedding mixtures for multi-interest candidate retrieval (2022) arXiv:2205.06205.
共有:

